自动化测试解决的问题:回归测试、压力测试、兼容性测试。
自动化测试的误区:自动化测试可以完全代替手工测试,自动化测试一定比手工测试更厉害,自动化测试可以捕获更多的bug,自动化测试适用于所有功能
什么样的web项目适合做自动化测试?
需求变动不频繁
项目周期长
项目需要回归测试
自动化测试在什么阶段开始–>功能测试完毕(手工测试)
web自动化属于黑盒测试(功能测试)
元素定位 元素定位就是通过元素的信息或元素层级结构来定位
selenium提供的8种定位元素方式
1 2 3 4 5 6 7 8 1. id 2. name 3. class_name 4. tag_name(<标签名.../>) 5. link_text(定位超链接a标签) 6. partial_link_text(定位超链接a标签 模糊) 7. XPath(基于元素路径) 8. CSS(元素选择器)
id定位 html规定id属性在整个html文档中必须是唯一的
el=driver.find_element(by=By.ID, value='id值')
打开百度输入内容进行查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.get("https://www.baidu.com" ) el = browser.find_element(by=By.ID, value='kw' ) el.send_keys('怪物猎人' ) browser.find_element(by=By.ID, value='su' ).click() time.sleep(20 ) browser.quit()
name定位 html中name属性值是可以重复的
1 2 3 4 5 6 7 8 9 10 11 12 13 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome() browser.get("https://www.baidu.com" ) browser.find_element(by=By.NAME,value='wd' ).clear() el = browser.find_element(by=By.NAME, value='wd' ) el.send_keys('索尼' ) browser.find_element(by=By.ID, value='su' ).click() time.sleep(20 ) browser.quit()
class name定位 根据元素class属性值定位元素,html通过class来定义元素的样式。如果class有多个属性值,只使用其中一个
1 2 3 4 5 6 7 8 9 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome() browser.get("https://www.bilibili.com/" ) browser.find_element(by=By.CLASS_NAME, value='channel-link' ).click() time.sleep(20 ) browser.quit()
查找第三个
1 2 3 4 5 6 7 8 9 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome() browser.get("https://www.bilibili.com/" ) browser.find_elements(by=By.CLASS_NAME, value='channel-link' )[2 ].click() time.sleep(20 ) browser.quit()
tag_name定位 通过标签名来定位,一般有多个。如果存在多个相同标签则返回第一个
1 2 3 4 5 6 7 8 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bydr = webdriver.Chrome() dr.get('https://www.csdn.net/' ) dr.find_elements(By.TAG_NAME, 'dl' )[0 ].click() time.sleep(20 )
link_text 定位a标签,link_text定位元素的内容必须全部匹配(不然会报错)
1 2 3 4 5 6 7 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.get('https://rinta.top/' ) browser.find_element(By.LINK_TEXT,'Python' ).click() time.sleep(20 )
partial_link_text 模糊匹配linktext定位找到元素,但是要保证唯一性
1 2 3 4 5 6 7 8 9 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.get('https://rinta.top/' ) browser.find_element(By.LINK_TEXT,'Python' ).click() time.sleep(5 ) browser.find_element(By.PARTIAL_LINK_TEXT,'AR' ).click() time.sleep(20 )
Xpath xpath是XML路径定位器,HTML与XML相似,所以也可以用xpath来定位。针对定位到多个元素时也可以下标取值,下标从1开始
1 2 3 //*[text()="xxx" ] //*[contains(@attribute,'xxx' )] //*[starts-with (@attribute,'xxx' )]
表达式
描述
nodename
选取此节点的所有子节点
/
从当前节点选取直接子节点
//
从当前节点选取子孙节点
.
选取当前节点
. .
选取当前节点的父节点
@
选取属性
*
任何元素
通过路径定位 绝对路径:以/开头,不能跳级
相对路径:以//开头,后跟元素名称,不知道名称可以用*代替(*代表所有元素)
1 2 3 4 5 6 7 8 9 10 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bydr = webdriver.Chrome() dr.get('https://www.bilibili.com/' ) dr.find_element(By.XPATH, value='//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[2]/div[1]/a[8]' ).click() time.sleep(20 ) //*
利用元素属性 dr.find_element(By.XPATH, value='//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[2]/div[1]/a[8]').click()# @修饰属性
属性和逻辑结合 通过and连接两个属性
//*[@id='id值' and @属性='属性值']
层级与属性结合 //*[@id='父级id值' ]/input
css选择器 css用来描述html元素的显示样式,在css中,选择题是一种模式用于选择需要添加样式的元素。
css定位常用策略:id选择器、class选择器、元素选择器、属性选择器、层级选择器
符号.代表class, 符号 # 代表id
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.get("https://www.baidu.com" ) el = browser.find_element(by=By.CSS_SELECTOR, value='#kw' ) el.send_keys('怪物猎人' ) time.sleep(20 ) browser.quit()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.get("https://www.bilibili.com/" ) el = browser.find_element(by=By.CSS_SELECTOR, value='#i_cecream > div.bili-feed4 > div.bili-header.large-header > div.bili-header__channel > div.right-channel-container > div.channel-items__left > a:nth-child(6)' el.click() time.sleep(20 ) browser.quit()
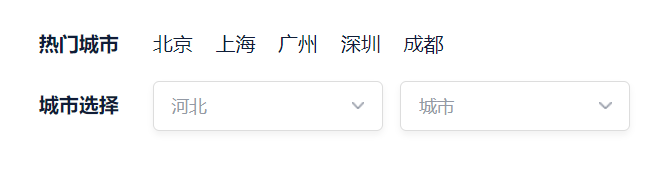
定位下拉框 通过css定位 [属性名=属性值]定位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.implicitly_wait(10 ) browser.get("https://www.ke.com/city/" ) time.sleep(5 ) time.sleep(3 ) el = browser.find_elements(By.CSS_SELECTOR, value='.chang-city' )[0 ] el.click() time.sleep(3 ) browser.find_element(By.CSS_SELECTOR, '[data-province_id="130000"]' ).click() time.sleep(10 ) browser.quit()
通过select类定位 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.implicitly_wait(10 ) browser.get( "https://signup.live.com/signup?lcid=1033&wa=wsignin1.0&rpsnv=13&ct=1667977589&rver=7.0.6737.0&wp=MBI_SSL&wreply=https%3a%2f%2foutlook.live.com%2fowa%2f%3fnlp%3d1%26signup%3d1%26RpsCsrfState%3d03e6f63b-7b44-e3a7-1cec-67445341a6de&id=292841&CBCXT=out&lw=1&fl=dob%2cflname%2cwld&cobrandid=90015&lic=1&uaid=5cd6f6e2004b4d5f96bcb3f20e670a07" ) time.sleep(5 ) browser.find_element(By.CSS_SELECTOR, value='#iSignupAction' ).click() time.sleep(3 ) el = browser.find_element(By.CSS_SELECTOR, value='#LiveDomainBoxList' ) el = browser.find_element(By.CSS_SELECTOR, value='[name = LiveDomainBoxList]' ) Select(el).select_by_value('hotmail.com' ) time.sleep(10 ) browser.quit()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.implicitly_wait(10 ) browser.get( "https://signup.live.com/signup?lcid=1033&wa=wsignin1.0&rpsnv=13&ct=1667977589&rver=7.0.6737.0&wp=MBI_SSL&wreply=https%3a%2f%2foutlook.live.com%2fowa%2f%3fnlp%3d1%26signup%3d1%26RpsCsrfState%3d03e6f63b-7b44-e3a7-1cec-67445341a6de&id=292841&CBCXT=out&lw=1&fl=dob%2cflname%2cwld&cobrandid=90015&lic=1&uaid=5cd6f6e2004b4d5f96bcb3f20e670a07" ) time.sleep(5 ) browser.find_element(By.CSS_SELECTOR, value='#iSignupAction' ).click() time.sleep(3 ) el = browser.find_element(By.CSS_SELECTOR, value='#LiveDomainBoxList' ) Select(el).select_by_index(1 ) time.sleep(10 ) browser.quit()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.implicitly_wait(10 ) browser.get( "https://signup.live.com/signup?lcid=1033&wa=wsignin1.0&rpsnv=13&ct=1667977589&rver=7.0.6737.0&wp=MBI_SSL&wreply=https%3a%2f%2foutlook.live.com%2fowa%2f%3fnlp%3d1%26signup%3d1%26RpsCsrfState%3d03e6f63b-7b44-e3a7-1cec-67445341a6de&id=292841&CBCXT=out&lw=1&fl=dob%2cflname%2cwld&cobrandid=90015&lic=1&uaid=5cd6f6e2004b4d5f96bcb3f20e670a07" ) time.sleep(5 ) browser.find_element(By.CSS_SELECTOR, value='#iSignupAction' ).click() time.sleep(3 ) el = browser.find_element(By.CSS_SELECTOR, value='#LiveDomainBoxList' ) Select(el).select_by_visible_text('hotmail.com' ) time.sleep(3 ) Select(el).select_by_visible_text('outlook.com' ) time.sleep(10 ) browser.quit()
警告框处理 Selenium中对处理弹出框的操作,有专用的处理方法,并且处理方式都一样
1 2 3 4 5 6 1. 获取弹出框对象alert=driver.switch_to.alert 2. 调用alert.text ---> 返回alert/confirm/prompt中文字信息 alert.accept() --->接受对话框选项 alert.dismiss() --->取消对话框选项
aler警告框 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.implicitly_wait(20 ) browser.get("https://www.runoob.com/try/try.php?filename=tryjs_alert" ) time.sleep(5 ) browser.switch_to.frame("iframeResult" ) browser.find_element(By.CSS_SELECTOR, '[value="显示警告框"]' ).click() time.sleep(3 ) alert = browser.switch_to.alert print (alert.text)alert.accept() time.sleep(10 ) browser.quit()
confirm确认框 prompt提示框 元素操作 .click()单击输入
clear()清楚文本
sendkeys()模拟输入,如果要上传本地文件也使用这个
获取元素信息的常用方法 size 返回元素大小
text 获取元素文本
get_attribute("xxx") 获取属性值,传递到参数为元素的属性名
is_displayed() 判断元素在页面上是否可见。
is_enabled() 判断元素是否可用,即元素是否可以进行交互操作,比如点击、输入等
is_selected() 判断元素是否选择,用来检查复选框或者单选按钮是否被选中
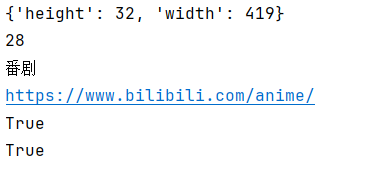
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.bilibili.com/" ) print (browser.find_element(By.CSS_SELECTOR,value='.nav-search-content' ).size)print (len (browser.find_elements(By.CSS_SELECTOR,value='.channel-link' )))time.sleep(2 ) el1=browser.find_element(By.CSS_SELECTOR,value='.nav-search-input' ) el1.send_keys('python' ) time.sleep(3 ) browser.refresh() el=browser.find_elements(By.CSS_SELECTOR,value='.channel-link' )[0 ] print (el.text)time.sleep(3 ) print (el.get_attribute('href' ))el.click() time.sleep(3 ) el2=browser.find_elements(By.CLASS_NAME,value='channel-link' )[3 ] print (el2.is_displayed())time.sleep(3 ) if el2.is_displayed(): el2.click() time.sleep(3 ) el3=browser.find_elements(By.CLASS_NAME,value='channel-link' )[4 ] print (el3.is_enabled())if el3.is_enabled(): el3.click() time.sleep(3 ) browser.close() time.sleep(5 ) browser.quit()
浏览器常用操作 maximize_window()最大化浏览器窗口
set_window_size(width,height)设置浏览器窗口大小
set_window_position设置浏览器窗口位置
back()模拟浏览器后退
forward()前进
refresh()刷新,在cookie中使用到
close()关闭当前窗口
quit()关闭浏览器驱动对象(会关闭所有窗口)
title获取页面title
current_url获取当前页面url
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() browser.set_window_position(320 ,150 ) time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) browser.get("https://www.bilibili.com/" ) time.sleep(2 ) browser.back() time.sleep(2 ) browser.forward() time.sleep(2 ) browser.quit()
关闭的窗口是创建的主窗口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.bilibili.com/" ) time.sleep(2 ) el1=browser.find_element(By.CSS_SELECTOR,value='.nav-search-input' ) el1.send_keys('python' ) time.sleep(3 ) browser.refresh() el=browser.find_elements(By.CLASS_NAME,value='channel-link' )[1 ] time.sleep(2 ) el.click() print (browser.current_url)time.sleep(2 ) browser.find_elements(By.CLASS_NAME,value='channel-link' )[3 ].click() time.sleep(3 ) browser.find_elements(By.CLASS_NAME,value='channel-link' )[4 ].click() time.sleep(3 ) browser.close() time.sleep(5 ) browser.quit()
鼠标和键盘操作 鼠标操作 click()是元素的事件,不是鼠标的事件。在selenium中操作鼠标的方法封装在ActionChains类中
实例化对象:action=ActionChains(driver)
方法:
context_click(element) 右击
double_click(element)双击
drag_and_drop(source,target) 拖动
move_to_element悬停
perform()执行以上所有鼠标操作,所有的方法都需要执行才生效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.common.by import Byimport timebrowser=webdriver.Chrome() action=ActionChains(browser) browser.get('https://www.bilibili.com' ) el1 = browser.find_element(By.CSS_SELECTOR, value='.nav-search-input' ) action.context_click(el1).perform() el1.send_keys('python' ) time.sleep(3 ) action.double_click(el1).perform() time.sleep(3 ) browser.refresh() el2 = browser.find_element(By.CSS_SELECTOR, value='.download-client-trigger__icon' ) time.sleep(3 ) action.move_to_element(el2).perform() time.sleep(5 ) browser.quit()
拖拽:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() action = ActionChains(browser) browser.get("https://www.baidu.com/" ) time.sleep(2 ) el1 = browser.find_element(By.CSS_SELECTOR, value='.title-content-title' ) el2=browser.find_element(By.CSS_SELECTOR,value='#kw' ) time.sleep(3 ) action.drag_and_drop(el1,el2).perform() time.sleep(3 ) browser.find_element(By.CSS_SELECTOR,value='#su' ).click() time.sleep(5 ) browser.quit()
drag_and_drop_by_offset(source,xoffset,yoffset)通过坐标偏移量执行拖拽
实例化匿名:ActionChains(driver).double_click(element).perform()
实名:action=ActionChains(driver)
键盘操作 常用的键盘操作:
send_keys(Keys.BACK_SPACE) 删除键
send_keys(Keys.SPACE) 空格键
send_keys(Keys.TAB) 制表键
send_keys(keys.ESCAPE) 回退键
send_keys(keys.ENTER) 回车键
send_keys(keys.CONTROL,'a') ctrl+a
send_keys(keys.CONTROL,'c') ctrl+c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from selenium import webdriverfrom selenium.webdriver import ActionChains, Keysfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() action = ActionChains(browser) browser.get("https://www.baidu.com/" ) time.sleep(2 ) el1 = browser.find_element(By.CSS_SELECTOR, value='#kw' ) time.sleep(3 ) el1.send_keys('Python1' ) time.sleep(3 ) el1.send_keys(Keys.BACK_SPACE) time.sleep(3 ) el1.send_keys(Keys.CONTROL, 'a' ) time.sleep(3 ) el1.send_keys(Keys.CONTROL, 'c' ) time.sleep(3 ) el1.send_keys(Keys.CONTROL, 'v' ) el1.send_keys(Keys.CONTROL, 'v' ) browser.find_element(By.CSS_SELECTOR, value='#su' ).click() time.sleep(5 ) browser.quit()
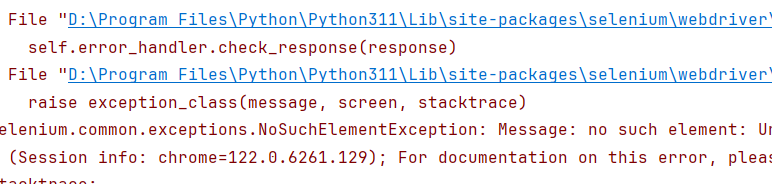
元素等待 在定位页面元素如果未找到,会在指定时间内一直等待的过程。在设置的时长内加载出来,会执行代码;没有加载出来则抛出异常
为什么要设置元素等待?网络速度慢、电脑配置低、服务器处理请求慢
隐式等待 隐式等待为全局设置 ,设置一次,作用于所有元素。一般为前置必写代码
定位元素时,如果能定位到元素则直接返回该元素,不触发等待;如果不能定位到该元素,则间隔一段时间后再去定位元素;如果在达到最大时长时还没有找到指定元素,则抛出元素不存在的异常NoSuchElementException
方法:driver.implicitly_wait(timeout),timeout为等待最大时长,单位秒。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) browser.implicitly_wait(10 ) time.sleep(2 ) el1 = browser.find_element(By.CSS_SELECTOR, value='#kj' ) el1.send_keys('python' )
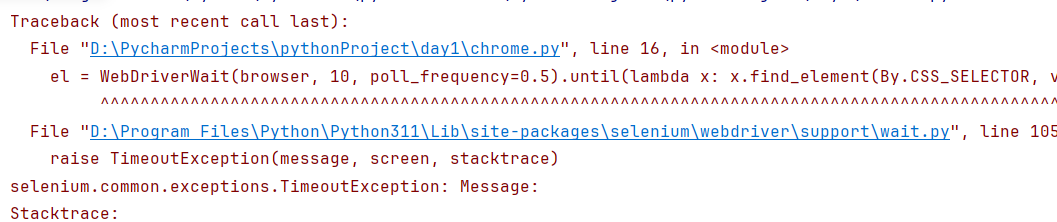
显式等待 对单个的元素有效
定位元素时,如果能定位到元素则直接返回该元素,不触发等待;如果不能定位到该元素,则间隔一段时间后再去定位元素;如果在达到最大时长时还没有找到指定元素,则抛出超时异常TimeoutException
1 2 3 4 5 6 7 8 9 10 1. 导包2. webDriverWait(driver, timeout, poll_frequency=0.5 ) 1 ) driver: 浏览器驱动对象 2 ) timeout: 超时的时长单位秒 3 ) poll_frequency: 检测间隔时间,默认0.5 s 3. 调用方法 until(method):直到...时 1 ) method: 函数名称,该函数用来实现对元素的定位 2 ) 一般使用匿名函数来实现:lambda x: x.find_element(By.方法,value) 4. element = WebDriverWait(driver, 10 , 1 ).util(lambda x: x.find_element(By.,value))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.wait import WebDriverWaitbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) el = WebDriverWait(browser, 10 , poll_frequency=0.5 ).until(lambda x: x.find_element(By.CSS_SELECTOR, value='#kj' )) el.send_keys('python' )
区别
显示等待针对单个元素生效,隐式等待针对全局元素生效
滚动条操作 html页面元素为动态显示,元素根据滚动条的下拉而加载。
Selenium没有提供操作滚动条的方法,但是提供了可执行JS脚本的方法,我们通过JS脚本来达到操作滚动条的目的
1 2 3 4 5 1. 设置JS脚本控制滚动条 js = "window.scrollTo(0,1000)" (0:左边距;1000:上边距 单位:像素) 2. selenium调用JS脚本的方法 driver.execute_scrip(js)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timefrom selenium.webdriver.support.select import Selectbrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://rinta.top" ) time.sleep(5 ) js = "window.scrollTo(0,10000)" browser.execute_script(js) time.sleep(3 ) time.sleep(10 ) browser.quit()
frame切换 frame是html页面中的一种框架,主要作用是在当前页面的指定区域显示一页面元素
1 2 3 4 5 6 7 形式一: <frameset cols ="25%,75%" > <frame src ="frame_a.htm" > </frame > <fram src ="frame_.htm" > </fram > </frameset > 形式二: <iframe name ="iframe_a" src ="demo_iframe.htm" width ="200" ,height ="200" > </iframe >
frame切换方法 1 2 3 4 1. 切换到指定frame的方法,frame_reference可以为frame框架的name、id 或者定位到的frame元素driver.switch_to.frame(frame_reference) 2. 恢复默认页面,在frame中操作其他页面一定要切换到默认页面driver.switch_to.default_content()
窗口切换 Selenium的默认焦点是在主窗口。在selenium中封装了获取当前窗口的句柄、获取所有窗口句柄和切换到指定句柄窗口的方法
句柄:handle ,窗口的唯一识别码
1 2 3 4 5 6 driver.current_window_handle driver.window_handles driver.switch_to.window(handle)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) time.sleep(5 ) browser.find_element(By.CSS_SELECTOR, '#kw' ).send_keys('小润' ) browser.find_element(By.CSS_SELECTOR, '#su' ).click() time.sleep(3 ) ch = browser.current_window_handle print (ch)browser.find_element(By.CSS_SELECTOR, '._around-mask_bo7t2_14' ).click() handles = browser.window_handles print (handles)time.sleep(3 ) for handle in handles: if handle != ch: browser.switch_to.window(handle) browser.find_elements(By.CSS_SELECTOR, '.text_BqlxX' )[2 ].click() time.sleep(10 ) browser.quit()
窗口截图与验证码 窗口截图 在执行出错的时候对当前窗口截图保存,可以通过图片直观地看到出错的原因
driver.get_screenshot_as_file(imgpath)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) time.sleep(5 ) browser.find_element(By.CSS_SELECTOR, '#kw' ).send_keys('小润' ) browser.find_element(By.CSS_SELECTOR, '#su' ).click() time.sleep(3 ) browser.get_screenshot_as_file('./screenshot.png' ) time.sleep(10 ) browser.quit()
根据时间戳获取截图:
browser.get_screenshot_as_file('./{}.png'.format(time.strftime("%Y_%m_%d_%H_%M_%S")))
验证码 selenium中没有对验证码处理的方式
去掉验证码(测试环境下采用)
设置万能验证码(生产环境和测试环境下采用)
验证码识别技术(通过Python-tesseract来识别图片类型验证码,识别率很难达到100%)
记录cookie(通过cookie进行跳过登录)
cookie
cookie是由web服务器生成的,并且保存至用户浏览器上的小型文本文件,可以包含用户相关信息。
cookie数据格式:键值对组成(python中的字典)
cookie产生:客户端请求服务器。如果服务器需要记录该用户状态,就向客户端颁发一个cookie数据
cookie使用:当浏览器再次请求该网站时,浏览器把请求的数据和cookie数据一同提交给服务器检查该cookie,以此来辨认用户状态
Cookie通常用于以下几个方面:
会话管理:用于跟踪用户的会话信息,例如在用户登录后保持用户的登录状态。
用户跟踪:用于记录用户的行为和偏好,以便网站提供个性化的体验。
高级功能:用于实现购物车、记住密码、广告定位等功能。
安全性:可以用于防止跨站点请求伪造(CSRF)等安全问题。
selenium操作cookie 1 2 3 4 5 6 7 get_cookie(name) get_cookies() add_cookie(cookie_dict)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) time.sleep(3 ) browser.add_cookie({"name" : "BDUSS" , "value" : "JwZG4zOUpyQU1RbXI2Z0VmbXVlU0ZuWmY0MUotcVZqcER-N3RqV0l-WUZveHRtSVFBQUFBJCQAAAAAAAAAAAEAAABZR~-XUmlubnQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUW9GUFFvRlSF" }) time.sleep(5 ) browser.refresh() time.sleep(10 ) browser.quit()
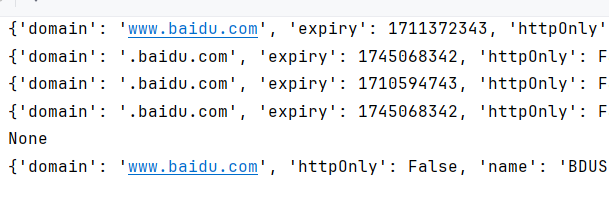
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from selenium import webdriverfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome() time.sleep(2 ) browser.maximize_window() browser.get("https://www.baidu.com/" ) time.sleep(3 ) browser.add_cookie({"name" : "BDUSS" , "value" : "JwZG4zOUpyQU1RbXI2Z0VmbXVlU0ZuWmY0MUotcVZqcER-N3RqV0l-WUZveHRtSVFBQUFBJCQAAAAAAAAAAAEAAABZR~-XUmlubnQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAUW9GUFFvRlSF" }) cookies=browser.get_cookies() for co in cookies: print (co) cookie=browser.get_cookie("name" ) print (cookie)print (browser.get_cookie('BDUSS' ))time.sleep(5 ) browser.refresh() time.sleep(10 ) browser.quit()
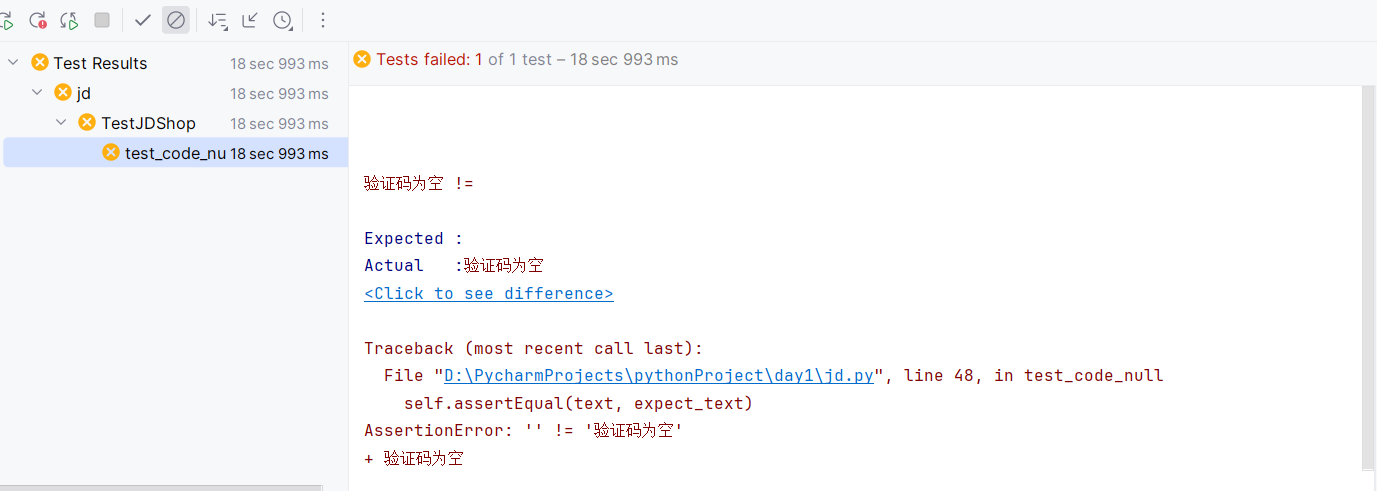
登录测试案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import timeimport unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byclass TestJDShop (unittest.TestCase): def setUp (self ): url = 'https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F%3Fcu%3Dtrue%26utm_source%3Dbaidu-pinzhuan%26utm_medium%3Dcpc%26utm_campaign%3Dt_288551095_baidupinzhuan%26utm_term%3D0f3d30c8dba7459bb52f2eb5eba8ac7d_0_40173755626041979e00a100eec87380' self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.get(url) self.driver.implicitly_wait(10 ) def tearDown (self ): time.sleep(2 ) self.driver.close() def test_code_null (self ): driver = self.driver driver.find_element(By.CSS_SELECTOR, '#sms-login' ).click() el1 = driver.find_element(By.CSS_SELECTOR, '#mobile-number' ) time.sleep(3 ) el1.send_keys('12345678901' ) time.sleep(3 ) el2 = driver.find_element(By.CSS_SELECTOR, '#send-sms-code-btn' ) el2.click() time.sleep(3 ) el3 = driver.find_element(By.CSS_SELECTOR, '#sms-code' ) el3.send_keys('324678' ) time.sleep(3 ) driver.find_element(By.CSS_SELECTOR, '#sms-login-submit' ).click() text = driver.find_element(By.CSS_SELECTOR, '.sms-box-error-msg' ).text expect_text = '验证码为空' print (text) try : self.assertEqual(text, expect_text) except AssertionError: driver.get_screenshot_as_file('./{}.png' .format (time.strftime("%Y_%m_%d_%H_%M_%S" ))) raise
PO模式 PO:page(页面),objecr(对象)
v1:不采用任何模型(线性模型)
v2:采用unittest框架
v3:业务代码和页面对象进行分离
v4:实际中的PO模式编写
v1 不能实现批量执行
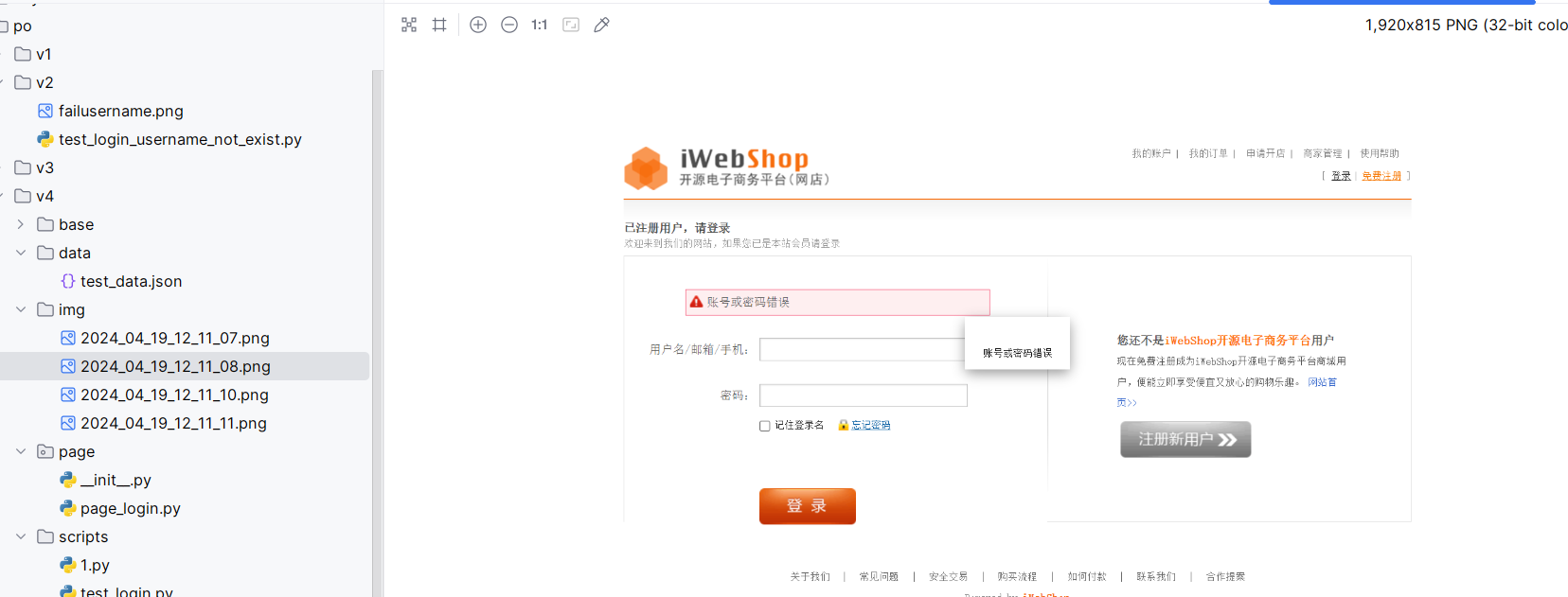
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import timefrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser=webdriver.Chrome() browser.maximize_window() browser.get('https://login.taobao.com/member/login.jhtml?spm=a21bo.jianhua.754894437.1.5af92a89NKrwFE&f=top&redirectURL=https%3A%2F%2Fwww.taobao.com%2F' ) browser.implicitly_wait(10 ) time.sleep(3 ) browser.find_element(By.XPATH,'//*[@id="login"]/div[2]/div/div[2]/a[1]' ).click() time.sleep(3 ) el1=browser.find_element(By.CSS_SELECTOR,'#fm-login-id' ) el1.send_keys('15234567888' ) time.sleep(2 ) el2=browser.find_element(By.CSS_SELECTOR,'#fm-login-password' ) el2.send_keys('Rinta1343' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR,'.class="fm-button fm-submit password-login' ).click() time.sleep(1 ) msg=browser.find_element(By.CSS_SELECTOR,'.login-error-msg' ) assert msg == '账号名或登录密码不正确' time.sleep(5 ) browser.quit()
验证密码:
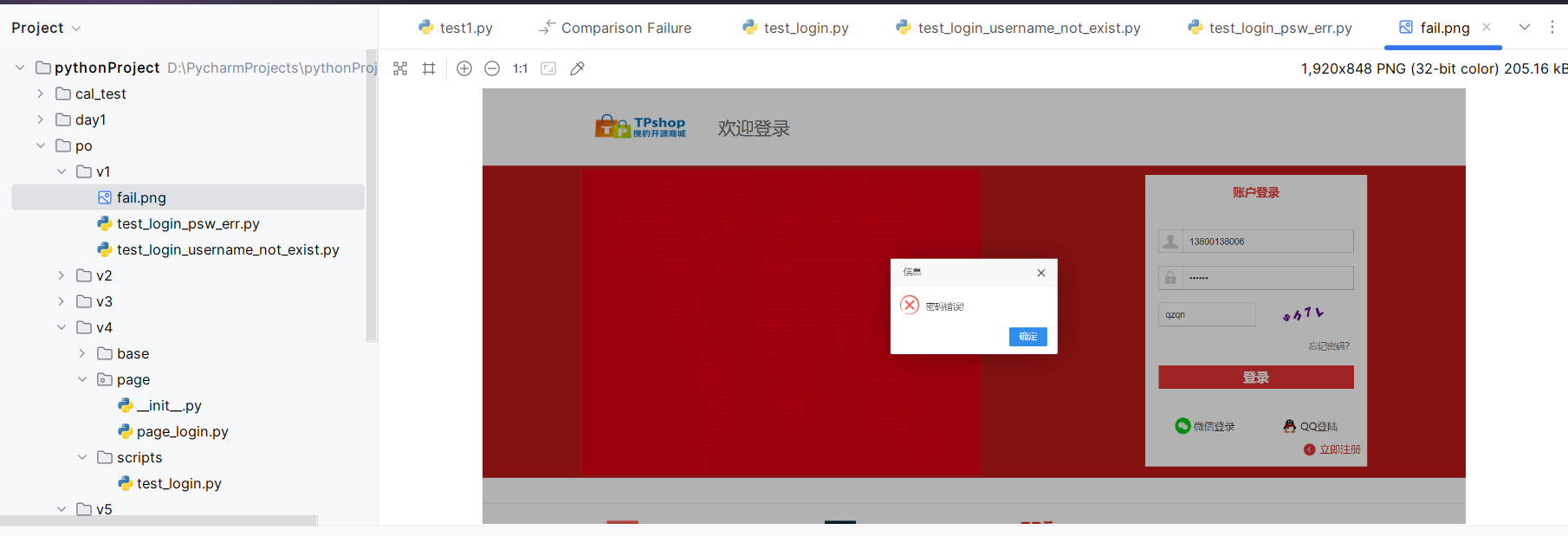
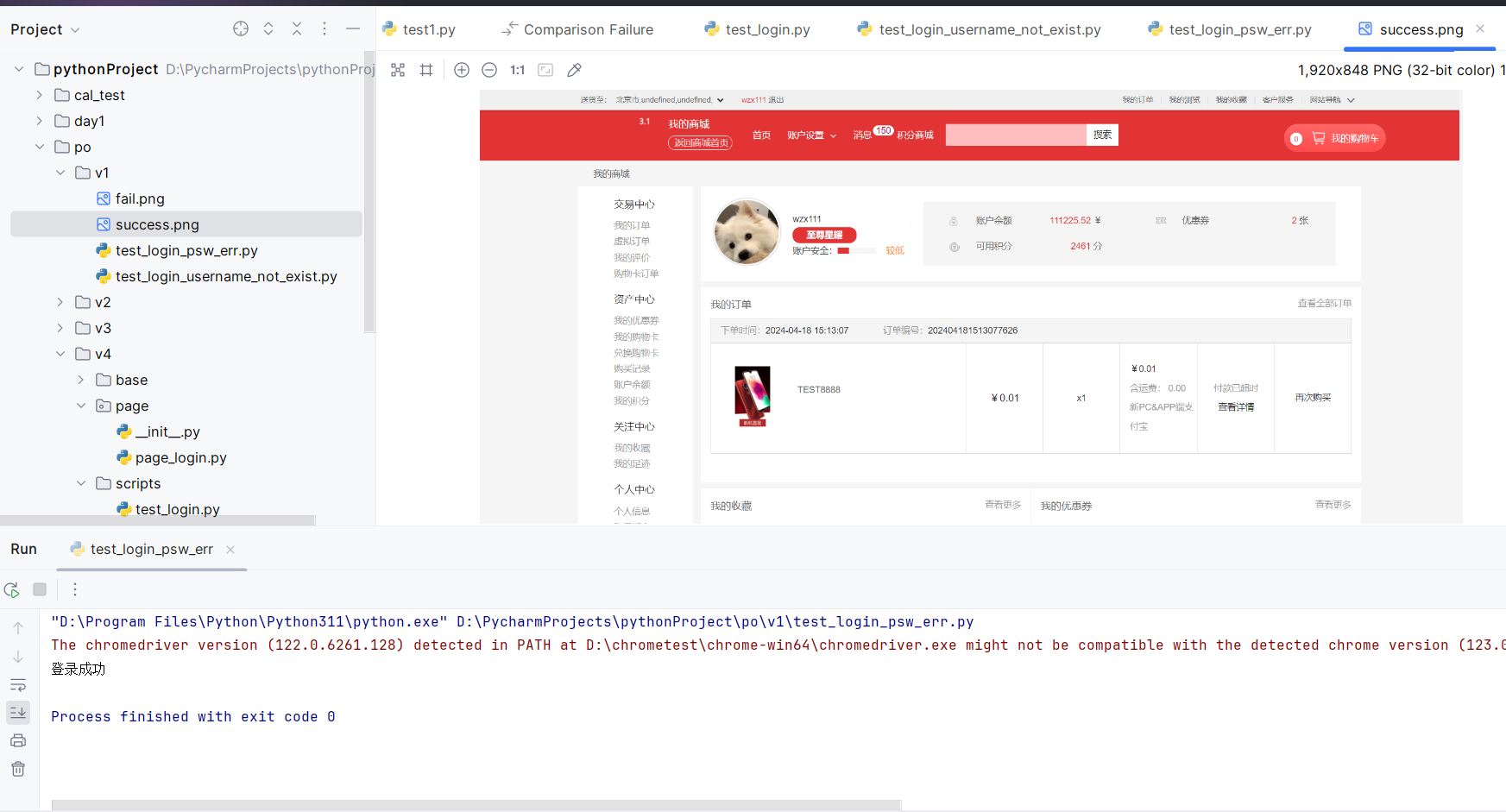
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import timefrom selenium import webdriverfrom selenium.common import NoSuchElementExceptionfrom selenium.webdriver.common.by import Bybrowser=webdriver.Chrome() browser.maximize_window() browser.get('http://demo5.tp-shop.cn/' ) browser.implicitly_wait(10 ) time.sleep(3 ) browser.find_element(By.LINK_TEXT,'登录' ).click() el1=browser.find_element(By.CSS_SELECTOR,'#username' ) el1.send_keys('13800138006' ) time.sleep(2 ) el2=browser.find_element(By.CSS_SELECTOR,'#password' ) el2.send_keys('123456' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR,'.J-login-submit' ).click() try : el3=browser.find_element(By.CSS_SELECTOR,'.J-umsg' ) print ('登录成功' ) browser.get_screenshot_as_file('./success.png' ) except NoSuchElementException: print ('登录失败' ) browser.get_screenshot_as_file('./fail.png' ) time.sleep(5 ) browser.quit()
换成正确密码:
1 el2.send_keys('soubao0316' )
缺点:数据和代码操作融合在一起,单线操作
v2 可以批量运行,代码冗余量大。没有实现页面对象与业务脚本的分离
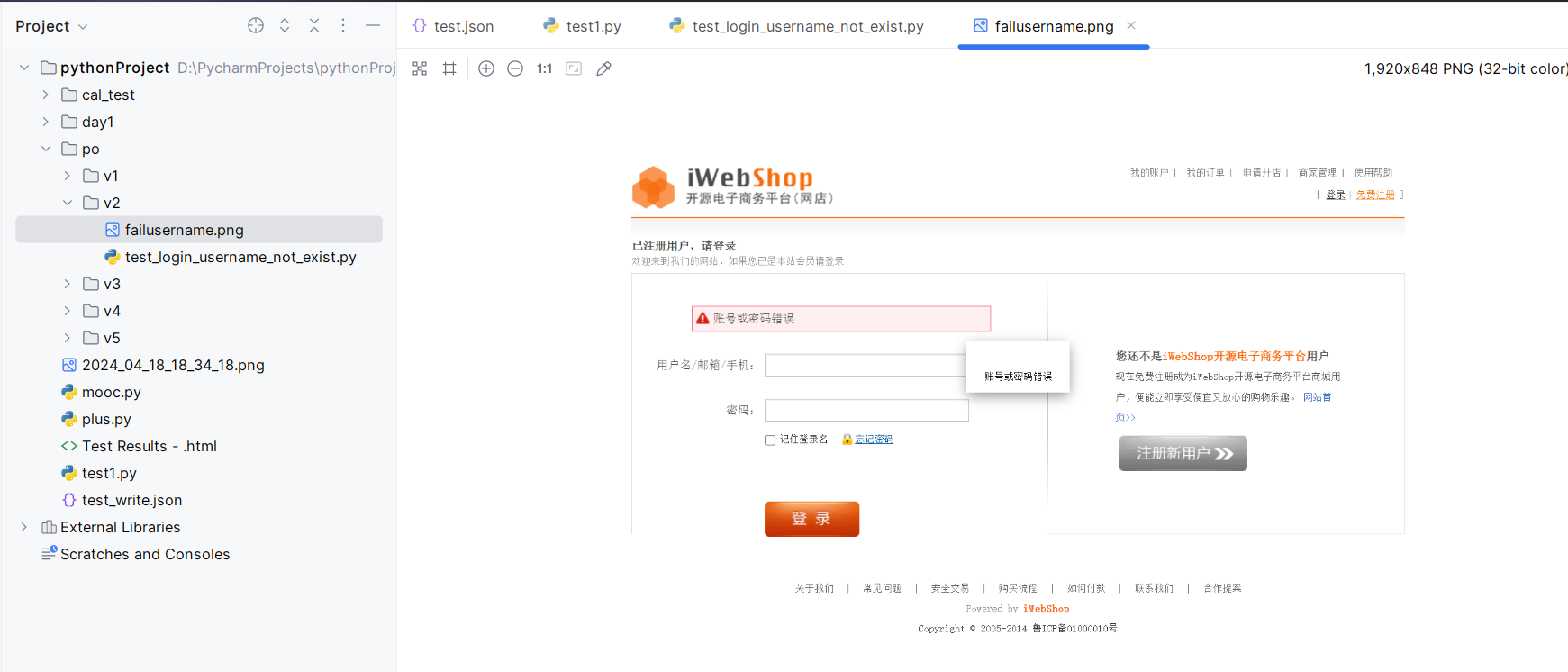
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 import timeimport unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byclass TestLogin (unittest.TestCase): browser = None @classmethod def setUpClass (cls ): cls.browser = webdriver.Chrome() cls.browser.maximize_window() cls.browser.get('http://localhost/iwebshopmaster/' ) cls.browser.implicitly_wait(10 ) @classmethod def tearDownClass (cls ): time.sleep(5 ) cls.browser.quit() def test_login_username_not_exist (self ): browser = self.browser time.sleep(3 ) browser.find_element(By.LINK_TEXT, '登录' ).click() time.sleep(3 ) el1 = browser.find_element(By.NAME, 'login_info' ) el1.clear() el1.send_keys('abc' ) time.sleep(2 ) el2 = browser.find_element(By.NAME, 'password' ) el2.clear() el2.send_keys('123456' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR, '.submit_login' ).click() time.sleep(1 ) msg = browser.find_element(By.CSS_SELECTOR, '.prompt' ) try : import unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byclass TestLogin (unittest.TestCase): browser = None @classmethod def setUpClass (cls ): cls.browser = webdriver.Chrome() cls.browser.maximize_window() cls.browser.get('http://localhost/iwebshopmaster/' ) cls.browser.implicitly_wait(10 ) @classmethod def tearDownClass (cls ): time.sleep(5 ) cls.browser.quit() def test_login_username_not_exist (self ): browser = self.browser time.sleep(3 ) browser.find_element(By.LINK_TEXT, '登录' ).click() time.sleep(3 ) el1 = browser.find_element(By.NAME, 'login_info' ) el1.clear() el1.send_keys('abc' ) time.sleep(2 ) el2 = browser.find_element(By.NAME, 'password' ) el2.clear() el2.send_keys('123456' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR, '.submit_login' ).click() time.sleep(1 ) msg = browser.find_element(By.CSS_SELECTOR, '.prompt' ).text try : self.assertEqual(msg, '账号名或登录密码不正确' ) except AssertionError: browser.get_screenshot_as_file('./failusername.png' ) def test_login_password_err (self ): browser = self.browser time.sleep(3 ) browser.find_element(By.LINK_TEXT, '登录' ).click() time.sleep(3 ) el1 = browser.find_element(By.NAME, 'login_info' ) el1.clear() el1.send_keys('ab' ) time.sleep(2 ) el2 = browser.find_element(By.NAME, 'password' ) el2.clear() el2.send_keys('1234567' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR, '.submit_login' ).click() time.sleep(1 ) msg = browser.find_element(By.CSS_SELECTOR, '.prompt' ).text try : self.assertEqual(msg, '账号或密码错误' ) except AssertionError: browser.get_screenshot_as_file('../reports/failpassword.png' ) self.assertEqual(msg, '账号名或登录密码不正确' ) except AssertionError: browser.get_screenshot_as_file('./failusername.png' ) def test_login_password_err (self ): browser = self.browser time.sleep(3 ) browser.find_element(By.LINK_TEXT, '登录' ).click() time.sleep(3 ) el1 = browser.find_element(By.NAME, 'login_info' ) el1.clear() el1.send_keys('ab' ) time.sleep(2 ) el2 = browser.find_element(By.NAME, 'password' ) el2.clear() el2.send_keys('1234567' ) time.sleep(10 ) browser.find_element(By.CSS_SELECTOR, '.submit_login' ).click() time.sleep(1 ) msg = browser.find_element(By.CSS_SELECTOR, '.prompt' ) try : self.assertEqual(msg, '账号或密码错误' ) except AssertionError: browser.get_screenshot_as_file('../reports/failpassword.png' )
v3 页面层以page开头,业务层以test开头
页面层级清晰,但是代码冗余量大
页面层代码page_login.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 """ 页面对象层 页面对象编写技巧: 类名:使用大驼峰将模块名称抄进来,有下划线去掉下划线 方法:根据业务需求每个操作步骤单独封装一个方法 方法名:page_XXX """ from selenium import webdriverfrom selenium.webdriver.common.by import Byclass PageLogin : def __init__ (self ): self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.implicitly_wait(10 ) self.driver.get('http://localhost/iwebshopmaster/' ) def page_click_login (self ): self.driver.find_element(By.LINK_TEXT, '登录' ).click() def page_input_username (self, username ): self.driver.find_element(By.NAME, 'login_info' ).send_keys(username) def page_input_pwd (self, pwd ): self.driver.find_element(By.NAME, 'password' ).send_keys(pwd) def page_click_login_btn (self ): self.driver.find_element(By.CLASS_NAME, 'submit_login' ).click() def page_get_text (self ): return self.driver.find_element(By.CSS_SELECTOR, '.prompt' ).text def page_login (self, username, pwd ): self.page_click_login() self.page_input_username(username) self.page_input_pwd(pwd) self.page_click_login_btn()
业务层代码test_login:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import timeimport unittestfrom parameterized import parameterizedfrom po.v3.page.page_login import PageLoginclass TestLogin (unittest.TestCase): def setUp (self ): self.login = PageLogin() def tearDown (self ): self.login.driver.quit() @parameterized.expand([('abc' , '123456' , '账号不存在' 'ab' , '123123' , '密码错误' ) def test_login (self, username, pwd, expect ): self.login.page_login(username, pwd) msg = self.login.page_get_text() try : self.assertEqual(msg, expect) except AssertionError: self.login.driver.get_screenshot_as_file('./{}.png' .format (time.strftime("%Y_%m_%d_%H_%M_%S" )))
v4 抽取v3版本的page页面公共方法—>base(基类/工具层)
page(页面对象):一个页面封装成一个对象,继承base
scripts(业务层):导包调用page页面
base/base.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import timefrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium import webdriverclass Base : chrome_testing_path=r"D:\chrometest\chrome-win64\chrome.exe" chromedriver_path=r"D:\chrometest\chrome-win64\chromedriver.exe" options = webdriver.ChromeOptions() options.binary_location = chrome_testing_path options.add_experimental_option('detach' , True ) service=Service(chromedriver_path) def __init__ (self ): self.driver = webdriver.Chrome(service=self.service,options=self.options) self.driver.maximize_window() self.driver.get( 'http://localhost/iwebshopmaster' ) def base_find_element (self, loc, timeout=30 , poll_frequency=0.5 ): return WebDriverWait(self.driver, timeout=timeout, poll_frequency=poll_frequency).until( lambda x: x.find_element(*loc)) def base_click (self, loc ): self.base_find_element(loc).click() def base_input (self, loc, value ): el = self.base_find_element(loc) el.clear() el.send_keys(value) def base_get_text (self, loc ): return self.base_find_element(loc).text def base_get_img (self ): self.driver.get_screenshot_as_file("../img/{}.png" .format (time.strftime("%Y_%m_%d_%H_%M_%S" )))
page/_init _.py:存放loc(查找元素的参数):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from selenium.webdriver.common.by import Bylogin_link = By.LINK_TEXT, "登录" login_username = By.NAME, "login_info" login_pwd = By.NAME, "password" login_btn = By.CSS_SELECTOR, ".submit_login" login_msg = By.CSS_SELECTOR, ".prompt"
page/page_login.py:定义page类(继承自base)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from po.v4 import pagefrom po.v4.base.base import Baseclass PageLogin (Base ): def page_click_login_link (self ): self.base_click(page.login_link) def page_input_username (self, username ): self.base_input(page.login_username, username) def page_input_pwd (self, pwd ): self.base_input(page.login_pwd, pwd) def page_click_login_btn (self ): self.base_click(page.login_btn) def page_get_text (self ): return self.base_get_text(page.login_msg) def page_get_screenshot (self ): self.base_get_img() def page_login (self, username, pwd ): self.page_input_username(username) self.page_input_pwd(pwd) self.page_click_login_btn()
scripts:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import unittestfrom parameterized import parameterizedfrom po.v4.page.page_login import PageLogindef get_data (): return [('abc' , '123456' , '账号不存在' ), ('ab' , '123123' , '密码错误' )] class TestLogin (unittest.TestCase): login = None @classmethod def setUpClass (cls ): cls.login = PageLogin() cls.login.page_click_login_link() @classmethod def tearDownClass (cls ): cls.login.driver.quit() @parameterized.expand(get_data( ) def test_login (self, username, pwd, expect ): self.login.page_login(username, pwd) msg = self.login.page_get_text() try : self.assertEqual(msg, expect) except AssertionError: self.login.page_get_screenshot()
数据驱动 以数据来驱动整个测试用例的执行,也就是测试数据决定测试结果,可以将用户的关注点放在测试数据的构建和维护上,而不是直接维护脚本,可以利用同样的过程对不同的数据进行测试,实现要依赖参数化。
数据驱动常用的格式:json、xml、excel、csv、txt
json的底层是字符串,和字典有区别
python字典和json之间的转换 python字典–>json字符串 dumps()
1 2 3 4 5 6 7 data = { 'id' :1 , 'name' :'Tom' , 'address' :'北京市海淀区' , 'school' :None } json_str=json.dumps(data)
1 2 3 4 5 6 7 8 9 10 11 12 import jsondata = { 'id' : 1 , 'name' : 'Tom' , 'address' : '北京市海淀区' , 'school' : None } print (type (data))json_str = json.dumps(data) print (json_str)print (type (json_str))
json字符串–>dict 键名必须在””中
loads()
1 2 json_str = '{"id":1,"name":"Tom","address":"北京市海淀","school":null}' dict_data=json.loads(json_str)
1 2 3 4 5 6 7 import jsonjson_str = '{"id":1,"name":"Tom","address":"北京市海淀","school":null}' dict_data=json.loads(json_str) print (type (json_str))print (dict_data)print (type (dict_data))
json读写 写json dump()
1 2 3 4 5 import jsonparam = '{"id":1,"name":"Tom","address":"北京市","school":null}' with open ('../test_write.json' , 'w' , encoding='utf-8' ) as f: json.dump(param, f, ensure_ascii=False )
读json load()
1 2 3 4 5 import jsonwith open ('../test_write.json' , 'r' , encoding='utf-8' ) as f: data = json.load(f) print (data)
将登录模块改为json数据驱动 test_login.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import jsonimport unittestfrom parameterized import parameterizedfrom po.v4.page.page_login import PageLogindef get_data (): with open ('../data/test_data.json' , 'r' , encoding='UTF-8' ) as f: data = json.load(f) test_list=[] for data in data: test_tuple= (data.get("username" ),data.get("pwd" ),data.get("expect" )) test_list.append(test_tuple) return test_list class TestLogin (unittest.TestCase): login = None @classmethod def setUpClass (cls ): cls.login = PageLogin() cls.login.page_click_login_link() @classmethod def tearDownClass (cls ): cls.login.driver.quit() @parameterized.expand(get_data( ) def test_login (self, username, pwd, expect ): self.login.page_login(username, pwd) msg = self.login.page_get_text() try : self.assertEqual(msg, expect) except AssertionError: self.login.page_get_screenshot()
json文件:
有几组数据就有几个testcase
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [ { "username" : "abc" , "pwd" : 123456 , "expect" : "账号不存在" } , { "username" : "ab" , "pwd" : 1234567 , "expect" : "密码错误" } , { "username" : "a" , "pwd" : 123456 , "expect" : "账号不合法" } , { "username" : "ab" , "pwd" : 12345 , "expect" : "密码错误" } ]
注意:操作时间过快会导致截图被覆盖,本来要截四张图变成两张
网页计算器案例 base: 查找元素、点击、获取value属性、截图
base>base.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import timefrom selenium.webdriver.support.wait import WebDriverWaitclass Base : def __init__ (self, driver ): self.driver = driver def base_find_element (self, loc, timeout=30 , poll=0.5 ): """ :param loc: 元素的定位信息,格式为元组 :param timeout: 默认超时时间,可以修改 :param poll: 访问频率莫,默认0.5 :return: 返回查找的元素 """ return WebDriverWait(self.driver, timeout=timeout, poll_frequency=poll).until(lambda x: x.find_element(*loc)) def base_click (self, loc ): self.base_find_element(loc).click() def base_value_get (self, loc ): return self.base_find_element(loc).get_attribute("value" ) def base_get_screenshot (self ): self.driver.get_screenshot_as_file("{}.png" .format (time.strftime("%Y_%m_%d_%H_%M_%S" )))
base>get_driver.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from selenium import webdriverfrom cal_test import pageclass GetDriver : driver=None @classmethod def get_driver (cls ): if cls.driver is None : cls.driver=webdriver.Chrome() cls.driver.maximize_window() cls.driver.get(page.url) return cls.driver @classmethod def quit_driver (cls ): if cls.driver: cls.driver.quit() cls.driver=None
data:
1 2 3 4 5 6 7 { "calc_001" : { "a" : 1 , "b" : 2 , "expect" : 3 } , "calc_002" : { "a" : 33 , "b" : 12 , "expect" : 45 } , "calc_003" : { "a" : 1212 , "b" : 12 , "expect" : 1224 } , "calc_004" : { "a" : 1211 , "b" : 11 , "expect" : 1222 } , "calc_005" : { "a" : 1213 , "b" : 13 , "expect" : 1226 } }
page>_init _.py
1 2 3 4 5 6 7 8 9 10 11 12 13 """以下为计算器配置数据""" from selenium.webdriver.common.by import Byurl="http://cal.apple886.com/" calc_add=By.CSS_SELECTOR,'#simpleAdd' calc_equal=By.CSS_SELECTOR,'#simpleEqual' calc_res=By.CSS_SELECTOR,'#resultIpt' calc_clear=By.CSS_SELECTOR,'#simpleClearAllBtn'
page>page_calc.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from selenium.webdriver.common.by import Byfrom cal_test import pagefrom cal_test.base.base import Baseclass PageCalc (Base ): def page_click_num (self, num ): for n in str (num): loc = By.CSS_SELECTOR, '#simple{}' .format (n) self.base_click(loc) def page_click_add (self ): self.base_click(page.calc_add) def page_click_eq (self ): self.base_click(page.calc_equal) def page_get_res (self ): return self.base_value_get(page.calc_res) def page_clear (self ): self.base_click(page.calc_clear) def page_get_screenshot (self ): self.base_get_screenshot() def page_add_calc (self, a, b ): self.page_click_num(a) self.page_click_add() self.page_click_num(b) self.page_click_eq()
scripts:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import unittestfrom parameterized import parameterizedfrom cal_test.base.get_driver import GetDriverfrom cal_test.page.page_calc import PageCalcfrom cal_test.tools.read_json import read_jsondef get_data (): datas = read_json("calc.json" ) arrs = [] for data in datas.values(): arrs.append((data.get("a" ), data.get("b" ), data.get("expect" ))) return arrs class TestCalc (unittest.TestCase): driver = None @classmethod def setUpClass (cls ): cls.driver = GetDriver().get_driver() cls.calc = PageCalc(cls.driver) @classmethod def tearDownClass (cls ): GetDriver().quit_driver() @parameterized.expand(get_data( ) def test_add_calc (self, a, b, expect ): self.calc.page_add_calc(a, b) try : self.assertEqual(self.calc.page_get_res(), str (expect)) except AssertionError: self.calc.base_get_screenshot() raise
tools>read_json.py:
1 2 3 4 5 6 7 8 9 import jsondef read_json (filename ): filepath="../data/" +filename with open (filepath, "r" , encoding="utf-8" ) as f: return json.load(f)
日志 可以查看错误提示信息。日志记录系统运行时的信息
作用:
调试程序
了解系统程序运行的情况是否正常
系统程序运行故障分析与问题定位
用来做用户行为分析和数据统计
日志级别 即日志信息的优先级、重要性或严重程度
日志级别
描述
DEBUG
调试级别,打印非常详细的日志信息,通常用于对代码的的调试
INFO
信息级别,打印一般的日志信息,突出强调程序的运行过程
WARNING
警告级别,打印警告日志信息,潜在错误的情形
ERROR
错误级别,打印错误异常信息,该级别的错误可能导致系统的一些功能无法正常执行
CRITICAL
严重错误级别,一个严重错误,系统可能无法继续运行
为程序指定一个日志级别后,程序会记录所有日志级别大于或等于指定级别的信息。一般建议只使用DEBUG、INFO、WARNING、ERROR
logging模块 1 2 3 4 5 6 7 import logginglogging.debug("this is a debug !" ) logging.info("this is a info" ) logging.warning("this is a warning" ) logging.error("this is a error" ) logging.critical("this is a critical" )
默认设置信息级别是warning
设置日志级别:
1 2 3 4 5 6 7 8 9 10 import logginglogging.basicConfig(level=logging.DEBUG) logging.debug("this is a debug !" ) logging.info("this is a info" ) logging.warning("this is a warning" ) logging.error("this is a error" ) logging.critical("this is a critical" )
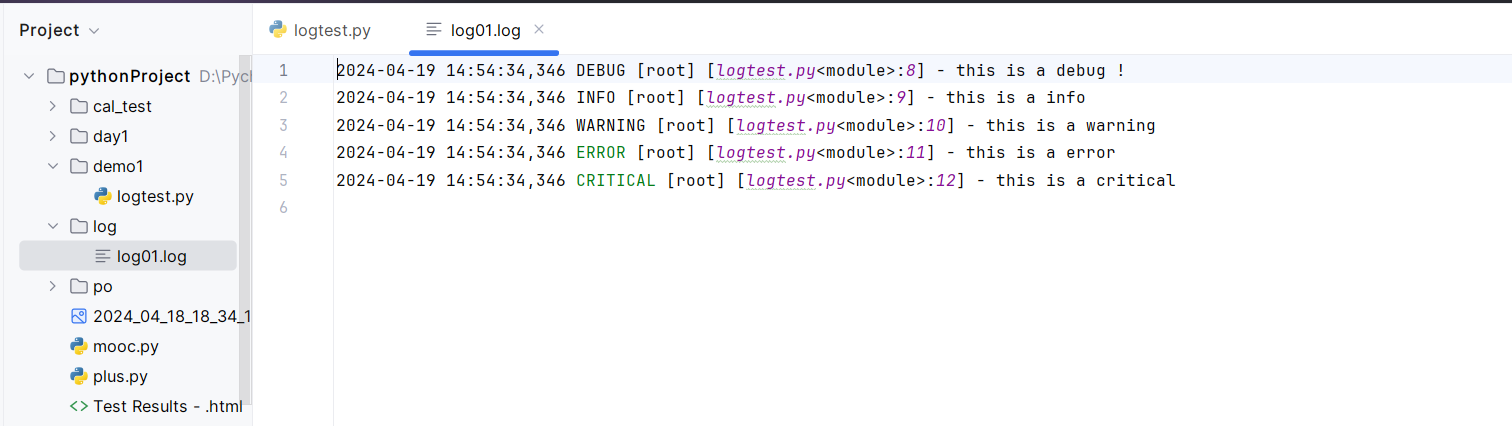
设置日志格式 1 2 3 4 5 6 7 8 9 10 11 import loggingfmt="%(asctime)s %(levelname)s [%(name)s] [%(filename)s%(funcName)s:%(lineno)d] - %(message)s" logging.basicConfig(level=logging.DEBUG,format =fmt) logging.debug("this is a debug !" ) logging.info("this is a info" ) logging.warning("this is a warning" ) logging.error("this is a error" ) logging.critical("this is a critical" )
保存到文件 1 2 logging.basicConfig(level=logging.DEBUG,format =fmt,filename='..\log\log01.log' )