
表
由行和列组成的二维表格
- 行,又叫记录
- 列,又叫字段
SQL语言(structured query language)
SQL语言主要分为:
- DQL:数据查询语言,如select
- DDL:数据定义语言,进行数据库、表的管理等,如create、drop
- DML:数据操作语言,增删改查,如insert、uupdate、delete
- TPL:事务处理语言,如begin transaction、commit、rollback
注释
- 单行注释:– 注释内容
- 多行注释:/* */
MySQL常用数据类型
- 整形 int
- 小整数tinyint
- 小数decimal:如decimal(5,2)表示共存5位数,小数占2位,不能超过2位;整数占3位
- 字符串varchar:如varchar(3)表示最多存3个 字符,一个中文或一个字母都占一个字符
- 日期实际datetime
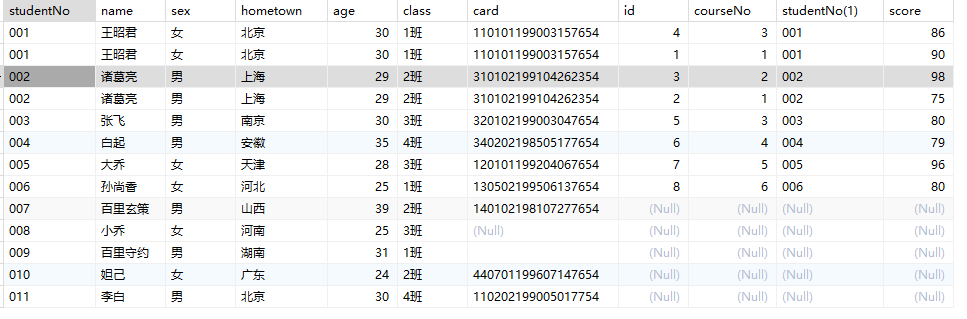
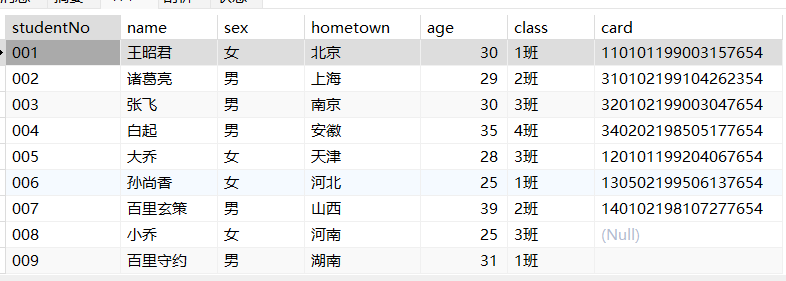
表、字段、记录
- 表:数据库中存储数据的基本单位
字段(列)–field 记录(行)–record
创建表 CREATE TABLE
1 | create table 表名( |

INSERT插入记录
1 | #值的顺序与字段顺序对应 |
1 | #部分字段设值,值的顺序与给出的字段顺序对应 |

1 | #插入多条记录,insert语句用分号隔开 |
1 | #一条insert语句插入多条记录 |
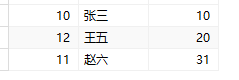
1 | #一条insert语句插入指定字段值 |
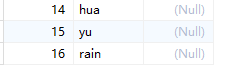
SELECT 简单查询
1 | SELECT * from 表名;#*表示全部的字段 |
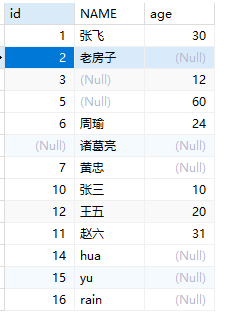
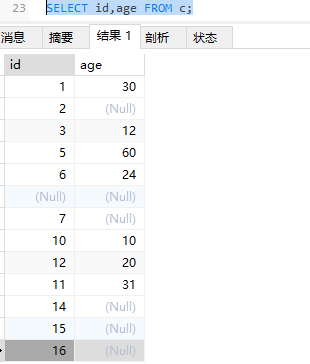
1 | #查询指定字段 |

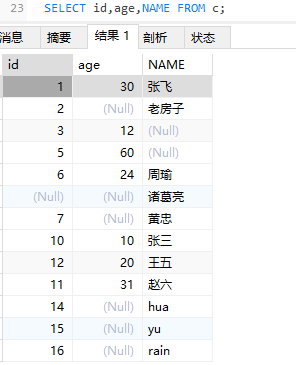
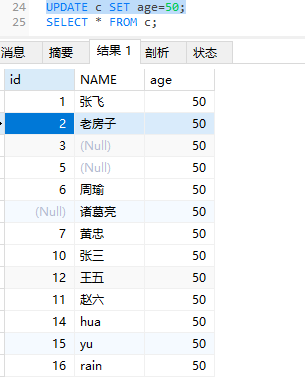
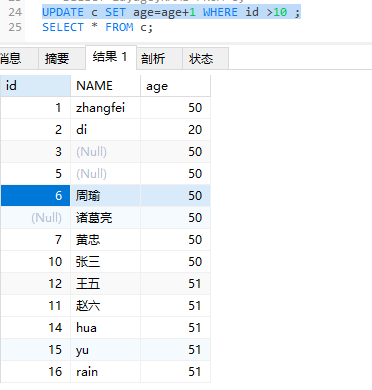
UPDATE 修改数据
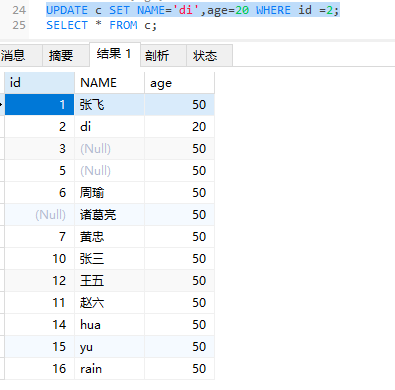
1 | update 表名 set 字段1=值1,字段2=值2 where 条件; |
1 | #设置条件修改 |
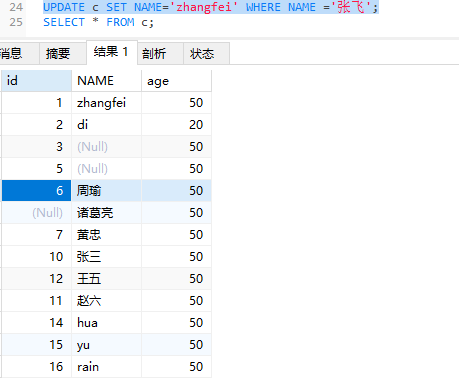
1 | #让id大于10的age都加一岁 |
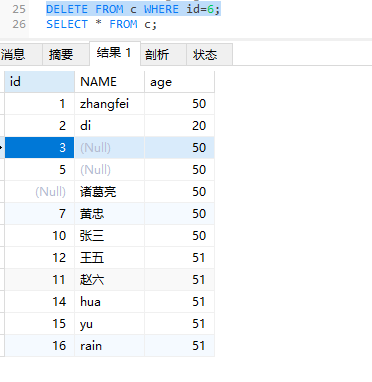
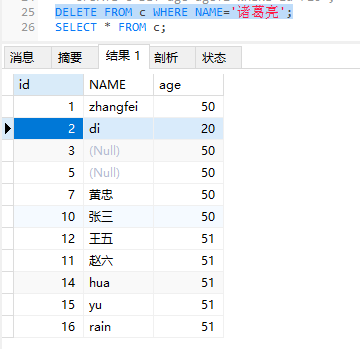
DELETE删除表的记录
1 | delete from 表名 where 条件; |
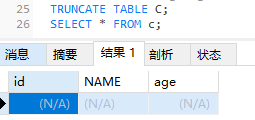
TEUNCATE删除表的所有数据,保留表结构
1 | truncate table 表名; |
DELETE与TRUNCATE区别
- 速度上,turncate>delete
- 如果只想删除部分数据用delete,带上where子句
- 如果想保留表而将所有数据删除,自增长字段恢复从1开始,用truncate,delete会从删除前的最大值开始增长
DROP TABLE删除表
1 | drop table 表名; |
字段的约束
常用的约束
- 主键(primary key):值不能重复,auto_increment代表值自动增长;
- 非空(not null):此字段不参与空值;
- 唯一(unique):此字段的值不允许重复
- 默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准
主键
创建带约束字段的表:
1 | create table 表名( |
1 | INSERT INTO d (id,name,age) VALUES (6,'www',12); |
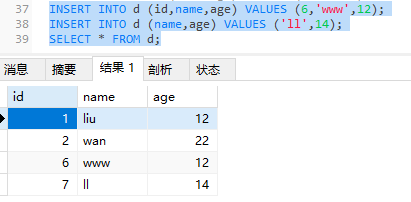
1 | -- 如果不指定字段,主键自增长的字段可以用占位符0或null |
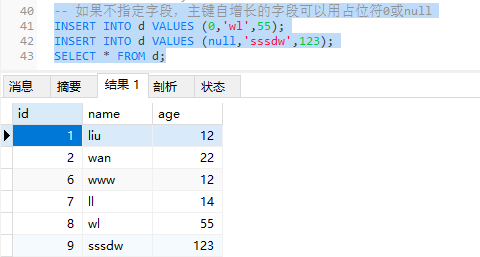
非空
1 | CREATE TABLE e( |
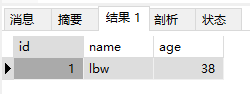
1 | INSERT INTO e (id,age) VALUES (2,22); |

唯一
此字段的值不允许重复
1 | CREATE TABLE f( |
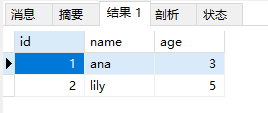
1 | INSERT INTO f VALUES(3,'ana',5); |

默认值
1 | CREATE TABLE g( |
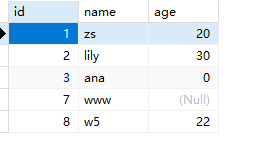
1 | INSERT INTO g VALUES(NULL,'w5',22); |
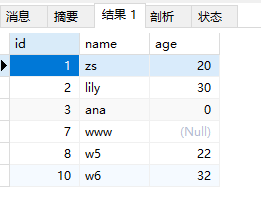
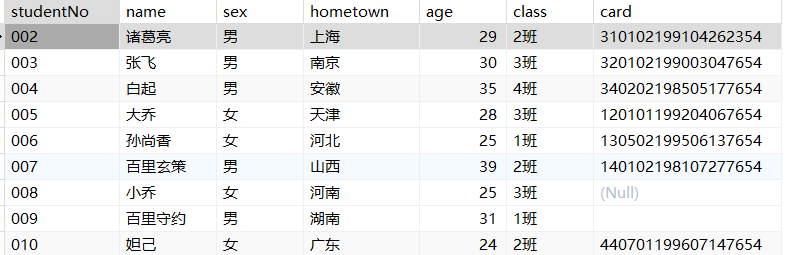
条件查询
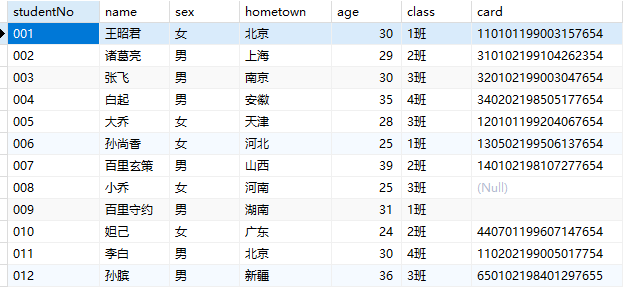
数据准备
1 | drop table if exists students; |
查询
1 | SELECT * FROM students; |
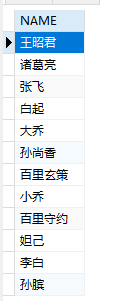
1 | SELECT `NAME` FROM students; |
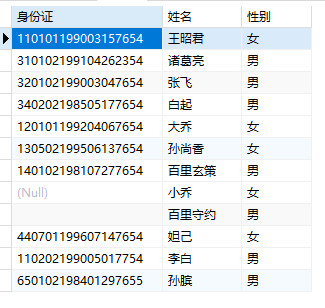
别名
字段的别名:
1 | SELECT card as 身份证,name as 姓名,sex as 性别 FROM students; |
表的别名:
1 | SELECT * FROM students as stu; |
去除重复distinct
1 | -- distinct可以过滤除select查询结果中重复的记录 |
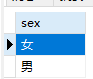
1 | SELECT sex,class from students; |
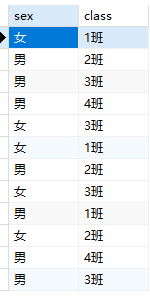
1 | SELECT DISTINCT sex,class from students; |
where子句
1 | SELECT * from students WHERE studentNO='001'; |

1 | SELECT name,class from students WHERE age=30; |
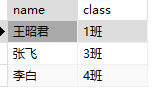
- select控制查询返回什么样的列(字段)
- where控制查询返回什么样的行(记录)
比较运算符
- 等于:=
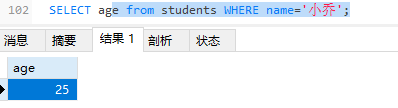
- 大于:>
- 大于等于:>=
- 小于:<
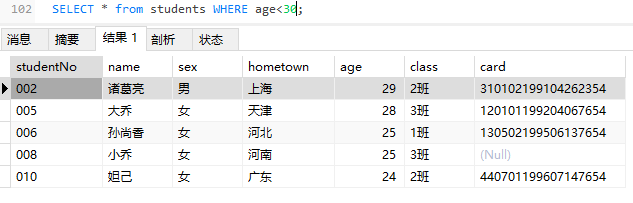
- 小于等于:<=
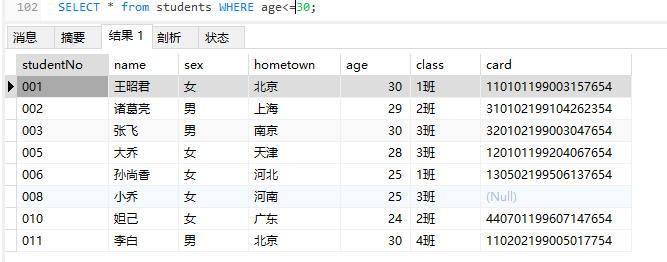
- 不等于:!=或<>
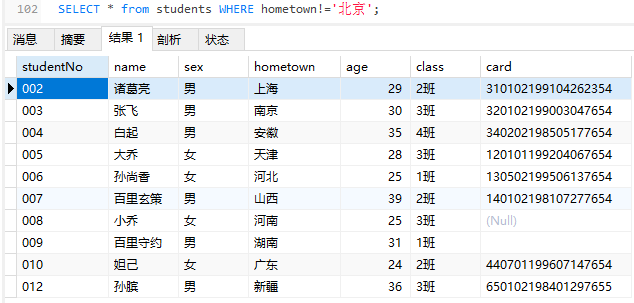
逻辑运算符
与and
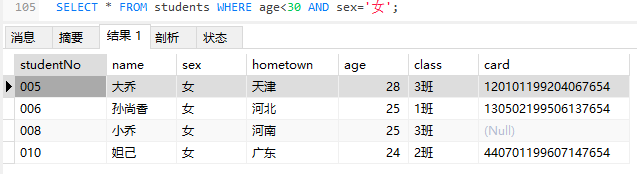
或or
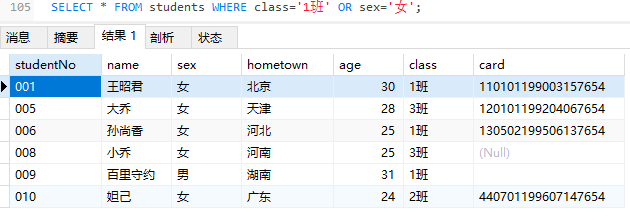
非not
模糊查询
like,表示模糊查询
%表示任意多个字符
下划线表示任意一个字符
1 | -- 查询姓名以孙开头的学生信息 |
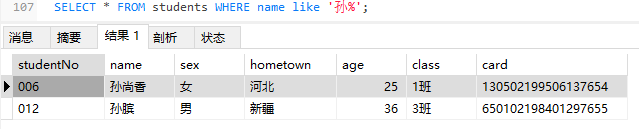
1 | -- 查询姓名以孙开头,且名字只有一个字的学生信息 |

1 | -- 查询名中带乔的学生信息 |
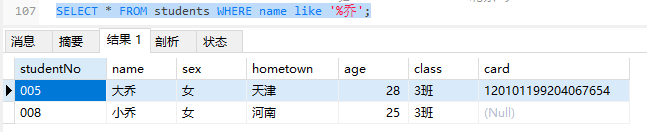
1 | -- 查询姓名中有白的学生信息 |

1 | -- 查询姓名为两个字的学生记录 |
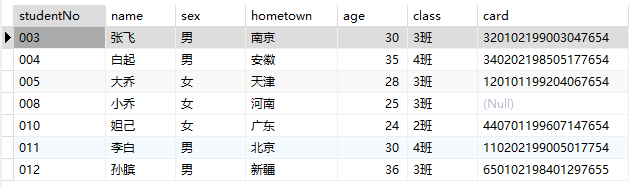


范围查找
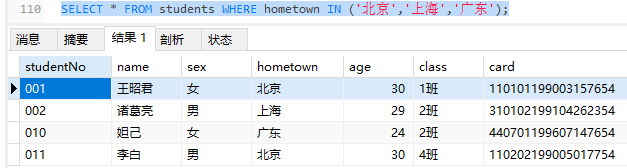
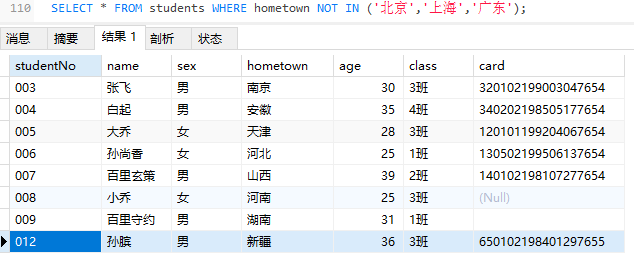
- in:表示在一个非连续的范围内
1 | SELECT * FROM students WHERE hometown IN ('北京','上海','广东'); |
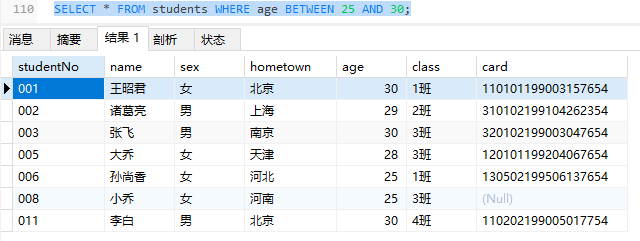
- between…and…:表示在一个连续的范围内
1 | SELECT * FROM students WHERE age BETWEEN 25 AND 30; |
1 | -- 查询age年龄在20或25或30的女生记录 |

空判断
在 SQL 中,NULL 代表未知值或缺失值,它与任何其他值(包括它自己)的比较结果都是未知的。因此,在 SQL 中,你不能使用 = 运算符来判断一个值是否为 NULL,因为任何值与 NULL 进行比较的结果都是未知的,包括自己与自己进行比较。
- 判断空:is null
1 | SELECT * FROM students WHERE card is NULL; |

- 判断非空:is not null
1 | SELECT * FROM students WHERE card is NOT NULL; |
where在update和delete
1 | UPDATE students SET class = '2班' WHERE age = 25 AND name='孙尚香'; |
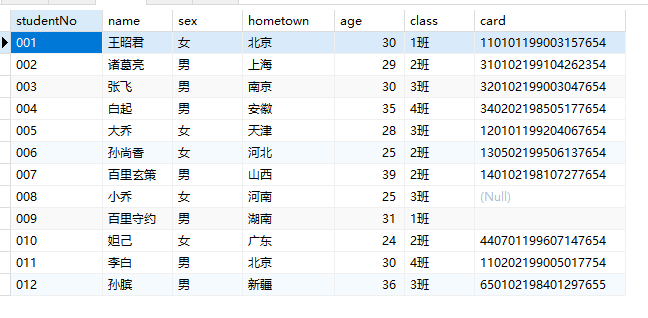
1 | DELETE FROM students WHERE class = '1班' and age >30; |
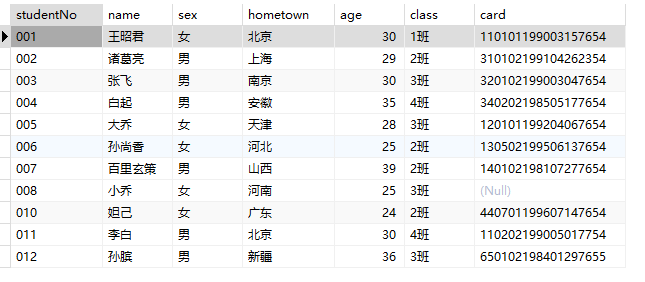
1 | UPDATE students SET class = '1班' WHERE name like '孙%'; |
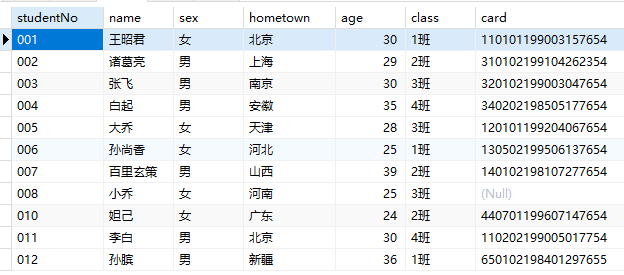
1 | DELETE FROM students WHERE (age BETWEEN 20 and 30) and sex = '男'; |
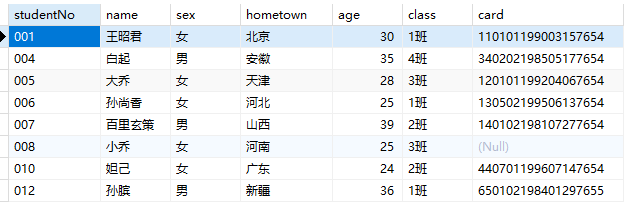
排序 order by
1 | select * from 表名 |
1 | SELECT * from students ORDER BY age; -- 默认为升序asc |
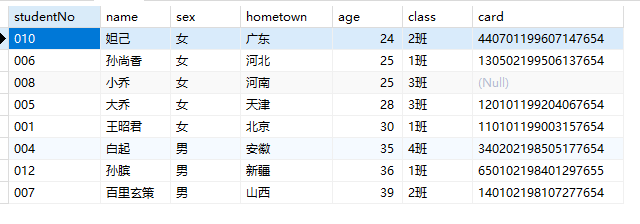
1 | SELECT * from students ORDER BY age DESC; |
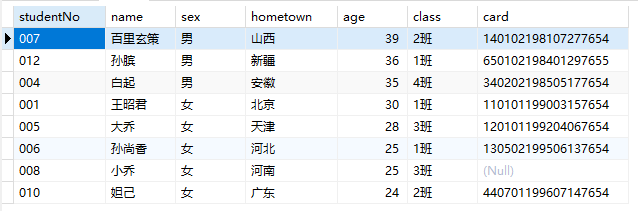
1 | -- 按年龄从大到小排序,年龄相同时按学号从小到大排序 |
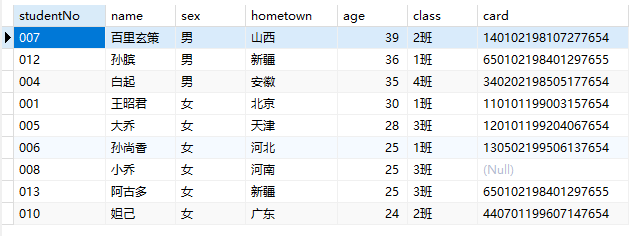
1 | -- where出现在oder by前面 |

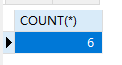
聚合函数
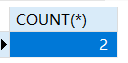
count总记录数
count(*) 表示总记录数,括号中写 * 与字段名、结果是相同的。字段记录有null时不同
1 | SELECT COUNT(*) FROM students |
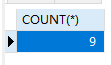
1 | -- 统计班级数 |
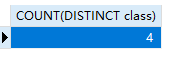
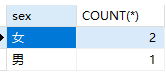
1 | -- 统计女同学的数量 |
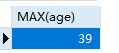
max最大值
max(字段)表示求此字段的最大值
1 | SELECT MAX(age) FROM students; |
1 | SELECT MAX(age) FROM students WHERE sex='女'; |
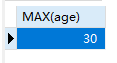
聚合函数不能用在where子句中
1 | select name from students where age = max(age); -- 错误 |
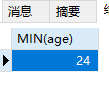
min最小值
min(字段)表示求此字段的最小值
1 | SELECT MIN(age) FROM students WHERE sex='女'; |
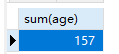
sum求和
1 | SELECT sum(age) FROM students WHERE sex='女'; |
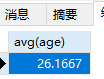
avg平均年龄
avg会忽略null
1 | SELECT avg(age) FROM students WHERE sex='女'; |
mod()取余
1 | MOD(dividend, divisor) |
数据分组
1 | select 聚合函数 from 表名 where 条件 group by 字段; |
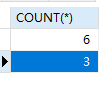
1 | SELECT sex,COUNT(*) FROM students GROUP BY sex; |
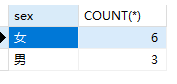
1 | SELECT sex,COUNT(*) FROM students WHERE class='1班' GROUP BY sex; |
1 | SELECT class,COUNT(*) 总数,avg(age),MAX(age) ,min(age) FROM students GROUP BY class |
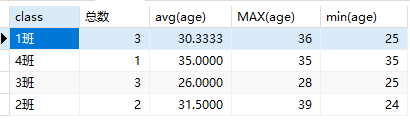
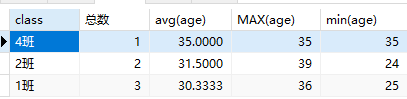
1 | SELECT class,COUNT(*) 总数,avg(age),MAX(age) ,min(age) FROM students WHERE NOT class='3班' GROUP BY class ORDER BY class DESC; |
分组后进行筛选
1 | select 字段1, 字段2, 聚合.. from 表名 |
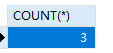
1 | -- 求班级人数大于2的班级 |
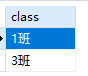
1 | -- 查询班级总人数大于2人的班级名称及班级对应的总人数 |
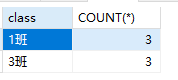
1 | -- 查询平均年龄大于30岁的班级名称和班级总人数 |
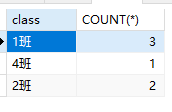
对比where和having
- where是对from后面指定的表进行筛选,是对原始数据进行筛选;
- having是对group by的结果进行筛选;
- having后面的条件可以用聚合函数,where后面的条件不可以使用聚合函数
WHERE用于筛选行,它指定了对哪些行进行聚合操作。WHERE子句筛选出满足条件的行,并将其传递给GROUP BY子句进行分组。GROUP BY用于对行进行分组,并对每个组应用聚合函数(如COUNT、SUM、AVG等)。GROUP BY子句指定了按照哪些列对行进行分组,聚合函数将在每个组上计算。
数据分页显示
limit 开始行,获取行数;
1 | select * from 表名 start,count -- start默认第一行 |

1 | -- 查询从第四条记录开始的三条记录 |

1 | -- limit总是出现在select语句的最后 |
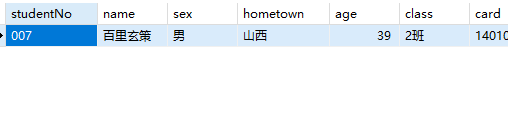
1 | -- 查询年龄最小的女同学信息 |

分页
已知每页显示m条数据,求:查询第n页的数据
1 | select * from students limit(n-1)*m ,m |
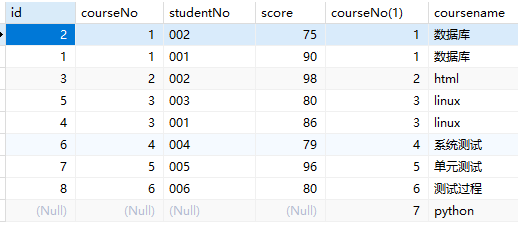
多表查询
通过连接运算实现
- 内连接
- 左连接
- 右连接
数据准备
1 | /* 创建学生表students */ |
内连接
查询的结果只显示两个表中满足连接条件的部分,即A∩B
1 | select * from 表1 |
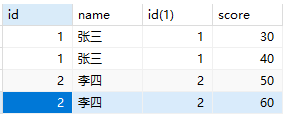
id(1)为别名
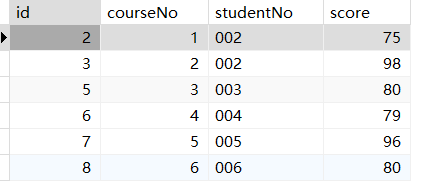
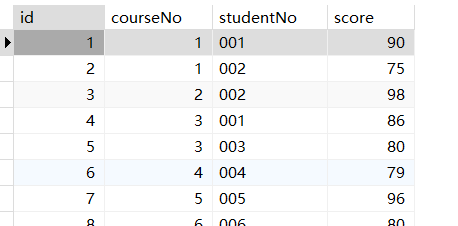
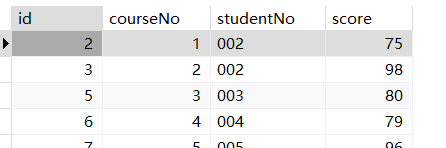
1 | SELECT * FROM students INNER JOIN scores ON students.studentNo=scores.studentNo; |
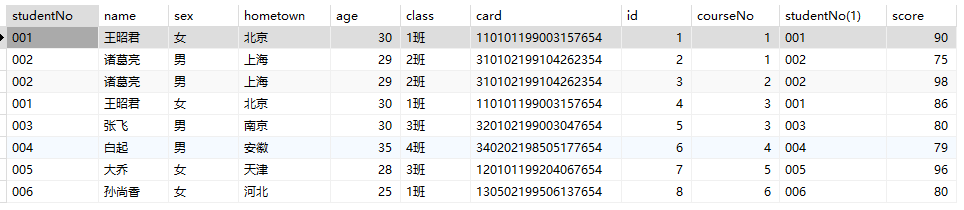
1 | SELECT name,courseNo,score FROM students,scores WHERE students.studentNo=scores.studentNo; |
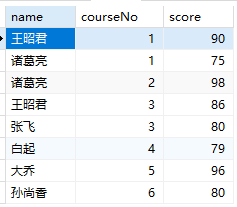
连接courses表和scores表
1 | -- |
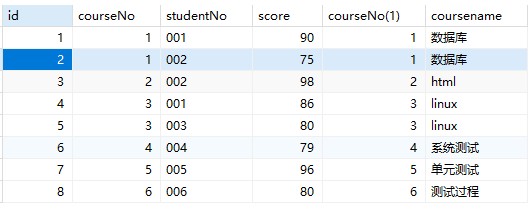
1 | SELECT name,courseNo,score FROM students s1 INNER JOIN scores s2 on s1.studentNo=s2.studentNo WHERE s1.name='王昭君'; |
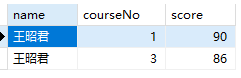
1 | SELECT name,score FROM students s1 INNER JOIN scores s2 on s1.studentNo=s2.studentNo WHERE s1.name='王昭君' AND s2.score<90; |
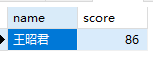
隐式内连接
1 | -- 隐式内连接 |
多表内连接
1 | SELECT * FROM students s1 INNER JOIN scores sc on s1.studentNo=sc.studentNo INNER JOIN courses s2 on sc.courseNo=s2.courseNo; |

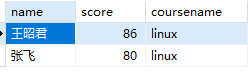
查询学生的linux成绩:
1 | SELECT name,score,coursename FROM students s1 INNER JOIN scores sc on s1.studentNo=sc.studentNo INNER JOIN courses s2 on sc.courseNo=s2.courseNo where s2.coursename='linux'; |
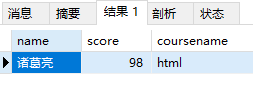
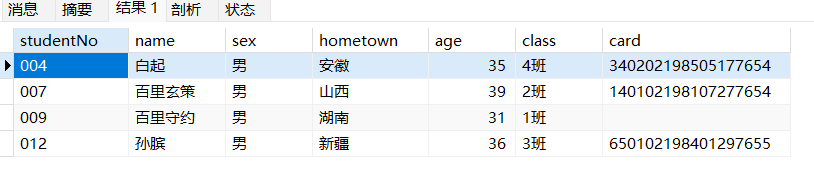
查询成绩最高的男生的信息
1 | SELECT name,score,coursename FROM students s1 INNER JOIN scores sc on s1.studentNo=sc.studentNo INNER JOIN courses s2 on sc.courseNo=s2.courseNo where s1.sex='男' ORDER BY sc.score DESC LIMIT 1; |
左连接
用于从左表中选择所有的行,并且对于右表中没有匹配的行,返回 NULL 值。
在 LEFT JOIN 中,左表是指位于 JOIN 关键字左侧的表,右表是指位于 JOIN 关键字右侧的表。LEFT JOIN 会返回左表的所有行,以及与左表中的行匹配的右表的行。如果右表中没有与左表中的行匹配的行,则会在结果中将右表的列设置为 NULL。
左连接适用于以下情况:
- 你想要保留左表的所有行,并将与左表中的行匹配的右表的行加入结果集。
- 左表是主表,右表是从表,你想要基于主表的内容来扩展结果集。
1 | select * from 表1 |
右连接
与左连接类似,不同之处在于它会返回右表的所有行,以及与右表中的行匹配的左表的行。如果左表中没有与右表中的行匹配的行,则会在结果中将左表的列设置为 NULL。
右连接适用于以下情况:
- 你想要保留右表的所有行,并将与右表中的行匹配的左表的行加入结果集。
- 右表是主表,左表是从表,你想要基于主表的内容来扩展结果集。
1 | select * from 表1 |
自关联
- 表中的相同字段所表示的含义不同
- 自关联是同一张表做连接查询
- 自关联下,一定要找到同一张表可关联的不同字段
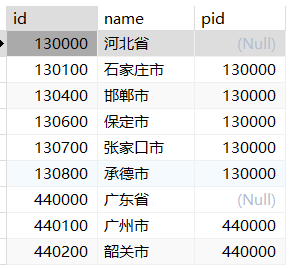
1 | -- 查询有多少个省 |
1 | -- 查询多少个市 |
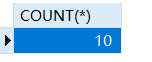
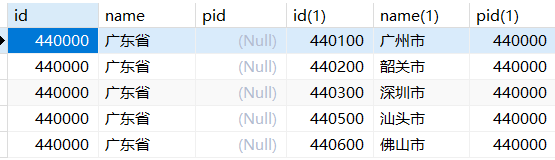
1 | -- 查询广东省所有的城市 |
子查询
一条select语句中,嵌入了另一个select语句,那么嵌入的select语句称之为子查询。
外层的第一条select语句为主查询
子查询和主查询的关系
子查询嵌入到主查询中
子查询是辅助主查询的,要么充当条件,要么充当数据源;
子查询是可以独立存在的语句,是一条完整的select语句
1
2-- 查询大于平均年龄的学生记录
SELECT * FROM students WHERE age>(SELECT AVG(age) FROM students);
标量子查询:子查询返回的结果只有一个值(一行一列),在主查询的条件中一般用比较运算符
1
2-- 查询30岁学生的成绩
SELECT score FROM scores WHERE studentNo IN(SELECT studentNo FROM students WHERE age =30)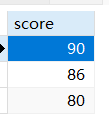
列子查询:子查询返回的结果是一列(一列多行),条件中一般用in
1 | -- 查询所有女生的信息和成绩 |

表级子查询:子查询的结果返回一张表(多行多列),一般和其他表联合查询
数据准备
1 | drop table if exists departments; |
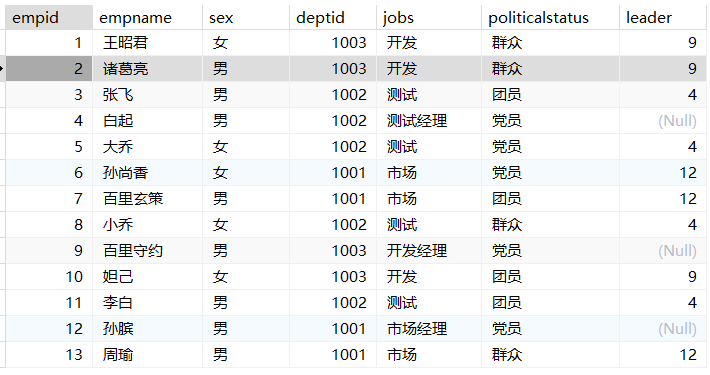
查询练习
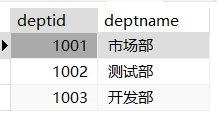
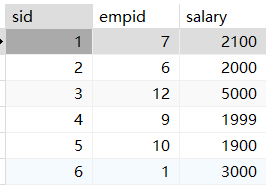
1 | -- 列出男职工的总数和女职工的总数 |
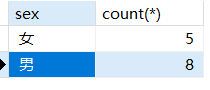
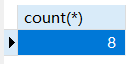
1 | -- 列出非党员职工的总数 |
1 | -- 列出所有职工工号、姓名以及所在部门名称 |
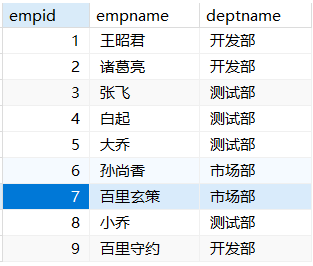
1 | -- 列出所有职工工号、姓名和对应工资 |
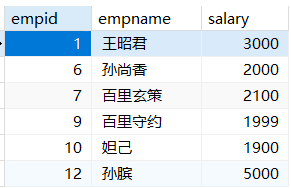
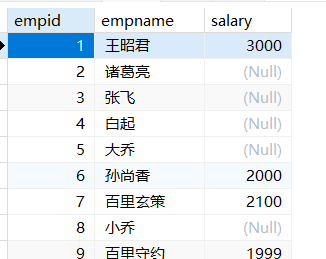
1 | -- 列出领导岗的姓名以及所在部门名称 |

1 | -- 列出职工总人数大于4的部门号和总人数 |
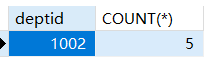
1 | -- 列出职工总人数大于4的部门号和部门名称 |
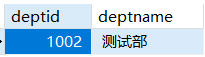
1 | -- 列出开发部和测试部的职工号,姓名 |
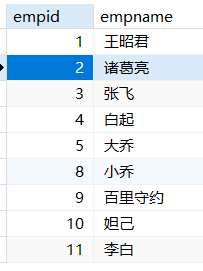
1 | -- 列出市场部所有女职工的姓名和政治面貌 |

1 | -- 显示出所有职工姓名和工资,包括没有工资的职工姓名 |
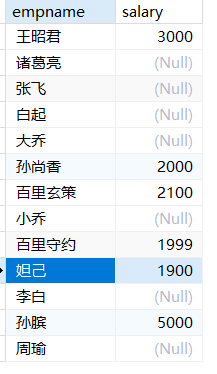
1 | -- 求不姓孙的所有职工的工资总和 |
MySQL常用内置函数
字符串函数
- 拼接字符串
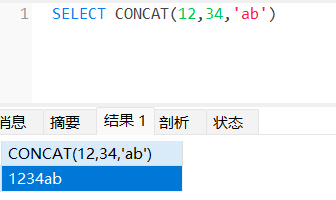
concat(str1,str2...)
1 | -- 把12,34,'ab'拼接为一个字符串'1234ab' |
- 计算字符串中字节个数
length(str)
1 | SELECT LENGTH('abc'); |
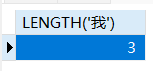
1 | -- 查询名字为3个字的学生信息 |

- 获取字符串中的字符数
char_length() - 截取字符串
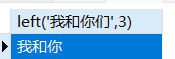
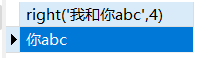
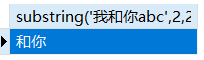
left(str,len)返回字符串str左端的len个字符,中文和英文字母一样right(str,len)返回字符串str右端的len个字符substring(str,pos,len)返回字符串str的位置pos起len个字符,pos从1开始计数
1 | SELECT left('我和你们',3) |
1 | SELECT right('我和你abc',4) |
1 | SELECT substring('我和你abc',2,2) |
1 | -- 查询所有学生信息,按年龄从大到小排序 |
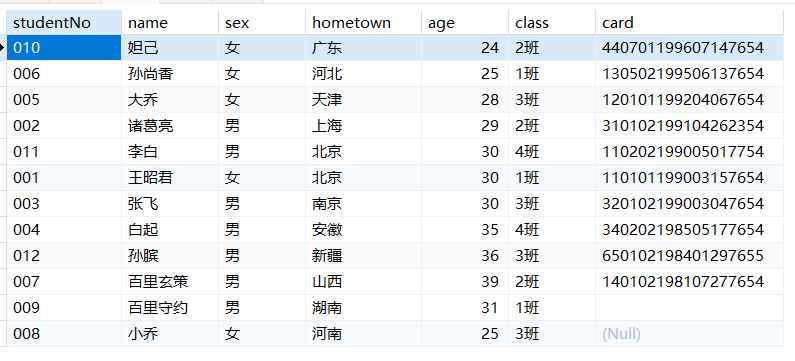
- 去除空格
ltrim(str)返回删除左侧空格的字符串rtrim(str)返回删除右侧空格的字符串trim(str)去除两侧空格
1 | SELECT LTRIM(' abcd '); |

数学函数
- 求四舍五入值
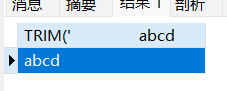
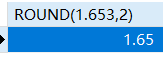
round(n,d),n表示原数,d表示小数位数,默认为0
1 | SELECT ROUND(1.653) |

1 | SELECT ROUND(1.653,2) |
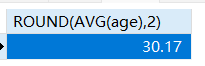
1 | -- 求学生的平均年龄并保留2位小数 |
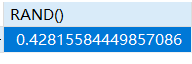
- 随机数
rand()产生从0到1.0的随机浮点数
1 | SELECT RAND(); |
1 | -- 随机排序 |
1 | -- 随机抽取一名学生 |
日期时间函数
- 当前日期
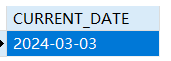
current_date()
1 | SELECT CURRENT_DATE |
- 当前时间
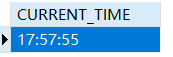
current_time()
1 | SELECT CURRENT_TIME |
- 当前时间(具体)
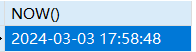
now()
1 | SELECT NOW() |
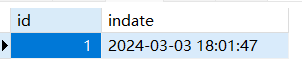
1 | -- 记录当前时间,比如下单时间 |
存储过程
存储过程procedure,即存储程序,是一条或者多条SQL语句的集合。
1 | -- 语法 |
1 | -- 创建存储过程 |

1 | -- 调用存储过程stu(),用CALL |
1 | -- 删除存储过程 |

视图
视图(View)是一种虚拟的表,它是由一个或多个表的行数据经过某种逻辑组合而形成的,它本身并不存储数据,只是对查询结果的一种抽象表示。通过视图,我们可以将复杂的查询、逻辑和数据组织进行封装,以简化数据访问和管理。视图的本质就是对查询的封装。
- 虚拟性:视图本身不存储数据,它只是对查询结果的一种逻辑表示。
- 透明性:使用视图的应用程序无需关心视图的底层实现,可以像访问普通表一样访问视图。
- 安全性:视图可以隐藏底层表的部分列或行,只向用户暴露需要的数据,从而提高数据安全性。
- 简化复杂性:通过视图,可以将复杂的查询逻辑封装起来,使用户可以通过简单的查询访问数据。
- 重用性:视图可以被多个查询或应用程序共享,提高了代码的重用性。
1 | -- 创建视图 |

1 | -- 查看视图 |
注意:视图的表是只读的。需要注意的是,视图中的数据是动态的,当基础表中的数据发生变化时,视图中的数据也会相应地更新。
1 | -- 视图和表进行内连接操作 |

1 | -- 删除视图 |
事务
事务是多条更改数据操作的sql语句集合,是一个操作序列,这些操作要么都执行,要么都不执行,是一个不可分割的工作单位
- 开启事务
begin:开启事务后执行修改UPDATE或者删除DELETE记录语句,变更会写到缓存中而不会立刻生效
- 回滚事务
rollback:放弃修改
- 提交事务
commit:将修改的事务写入实际的表中
1 | BEGIN; |
1 | -- 回滚操作 |

如果开启了一个事务,之后没有rollback也没有commit,系统出现了错误,会默认rollback
1 | -- 开启事务,删除学生信息和成绩,提交事务使两个表的删除同时生效 |

索引
可以加快select查询的速度,但是会降低更新表的速度,因为在保存文件的同时会同时保存索引文件。可以在更改记录前先删除索引
创建索引
1 | create index 索引名称 on 表名(字段名称(长度)) |
1 | -- 为students表的age字段创建索引,名为age_index |
1 | -- where条件后面的字段,数据库系统会自动查找是否有索引 |
查看索引
1 | show index from 表名 |

系统会为主键自动创建索引
删除索引
1 | drop index 索引名 on 表名; |

使用命令行
使用数据库
1 | -- 登录 |
1 | mysql -u root -p |
1 | -- 查看数据库 |
1 | -- 打开数据库 |
1 | -- 查看数据库中的表 |
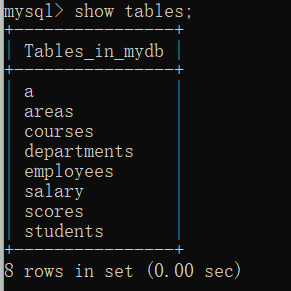
1 | -- 查询内容 |
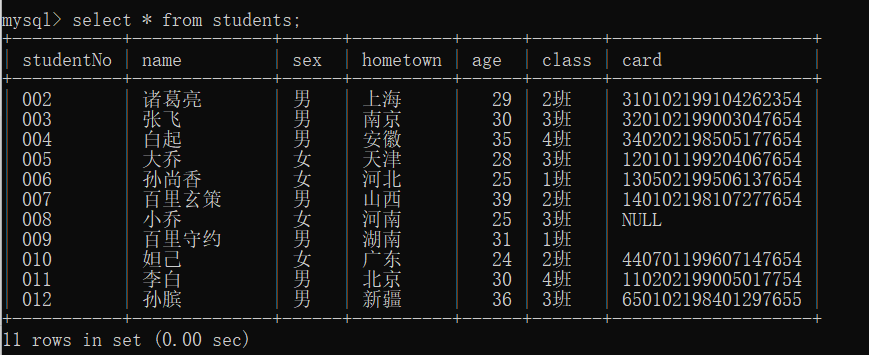
可以使用chcp 65001将命令行编码方式改为utf-8
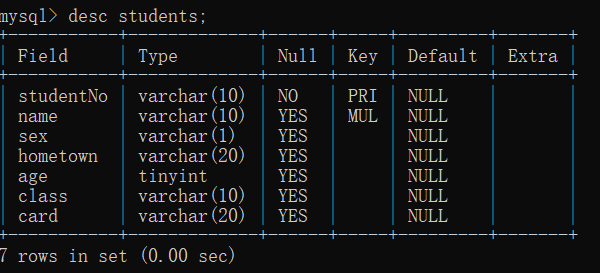
1 | -- 查看表的结构 |
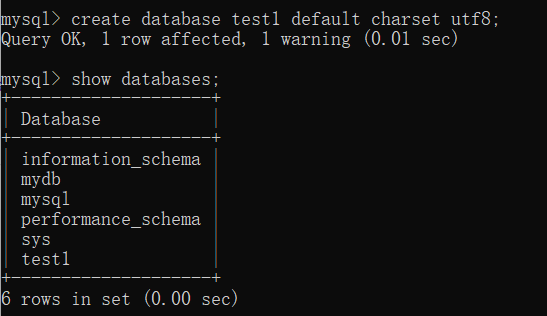
1 | -- 创建数据库 |
1 | -- 删除数据库 |
修改用户密码
1 | grant all on 数据库名 to 用户名@'登录主机' indentified by '密码' with grant option; |
grant all on:代表为用户赋权;- 数据库名:可以是*,代表所有数据库;
- 表名:可以是*,代表所有表,
to 用户名:指定要创建用户的名称@'登录主机':@localhost代表只能在本机登录,@’%‘代表可以远程